
It’s…it’s a histogram. – Dr. Grant
Okay. So maybe that isn’t the exact quote. But I think Dr. Grant would have been equally thrilled had he known the power of color histograms.
And more importantly, when the power goes out, the histograms don’t eat the tourists.
So, what exactly is a histogram? A histogram represents the distribution of colors in an image. It can be visualized as a graph (or plot) that gives a high-level intuition of the intensity (pixel value) distribution. We are going to assume a RGB color space in this example, so these pixel values will be in the range of 0 to 255. If you are working in a different color space, the pixel range may be different.
When plotting the histogram, the X-axis serves as our “bins”. If we construct a histogram with 256 bins, then we are effectively counting the number of times each pixel value occurs. In contrast, if we use only 2 (equally spaced) bins, then we are counting the number of times a pixel is in the range [0, 128) or [128, 255]. The number of pixels binned to the X-axis value is then plotted on the Y-axis.
OpenCV and Python versions:
This example will run on Python 2.7 and OpenCV 2.4.X/OpenCV 3.0+.
By simply examining the histogram of an image, you get a general understanding regarding the contrast, brightness, and intensity distribution.
This post will give you an OpenCV histogram example, from start to finish.
Application to Image Search Engines
In context of image search engines, histograms can serve as feature vectors (i.e. a list of numbers used to quantify an image and compare it to other images). In order to use color histograms in image search engines, we make the assumption that images with similar color distributions are semantically similar. I will talk more about this assumption in the “Drawbacks” section later in this post; however, for the time being, let’s go ahead and assume that images with similar color distributions have similar content.
Comparing the “similarity” of color histograms can be done using a distance metric. Common choices include: Euclidean, correlation, Chi-squared, intersection, and Bhattacharyya. In most cases, I tend to use the Chi-squared distance, but the choice is usually dependent on the image dataset being analyzed. No matter which distance metric you use, we’ll be using OpenCV to extract our color histograms.
Touring Jurassic Park
Let’s imagine that we were along with Dr. Grant and company on their first Jurassic Park tour. We brought along our cell phone to document the entire experience (and let’s also pretend that camera phones were a “thing” back then). Assuming we didn’t pull a Dennis Nedry a have our face eaten by a Dilophosaurus, we could later download the pictures from our smartphones to our computers and compute histograms for each of the images.
At the very beginning of the tour we spent a lot of times in the labs, learning about DNA and witnessing the hatching of a baby velociraptor. These labs have a lot of “steel” and “gray” colors to them. Later on, we got into our jeeps and drove into the park. The park itself is a jungle — lots of green colors.
So based on these two color distributions, which one do you think the Dr. Grant image above is more similar to?
Well, we see that there is a fair amount of greenery in the background of the photo. In all likelihood, the color distribution of the Dr. Grant photo would be more “similar” to our pictures taken during the jungle tour vs. our pictures taken in the lab.

Using OpenCV to Compute Histograms
Now, let’s start building some color histograms of our own.
We will be using the cv2.calcHist function in OpenCV to build our histograms. Before we get into any code examples, let’s quickly review the function:
cv2.calcHist(images, channels, mask, histSize, ranges)
- images: This is the image that we want to compute a histogram for. Wrap it as a list:
[myImage]. - channels: A list of indexes, where we specify the index of the channel we want to compute a histogram for. To compute a histogram of a grayscale image, the list would be
[0]. To compute a histogram for all three red, green, and blue channels, the channels list would be[0, 1, 2]. - mask: I haven’t covered masking yet in this blog yet, but essentially, a mask is a
uint8image with the same shape as our original image, where pixels with a value of zero are ignored and pixels with a value greater than zero are included in the histogram computation. Using masks allow us to only compute a histogram for a particular region of an image. For now, we’ll just use a value ofNonefor the mask. - histSize: This is the number of bins we want to use when computing a histogram. Again, this is a list, one for each channel we are computing a histogram for. The bin sizes do not all have to be the same. Here is an example of 32 bins for each channel:
[32, 32, 32]. - ranges: The range of possible pixel values. Normally, this is
[0, 256]for each channel, but if you are using a color space other than RGB (such as HSV), the ranges might be different.
Now that we have an understanding of the cv2.calcHist function, let’s write some actual code.
# import the necessary packages
from matplotlib import pyplot as plt
import numpy as np
import argparse
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", required = True, help = "Path to the image")
args = vars(ap.parse_args())
# load the image and show it
image = cv2.imread(args["image"])
cv2.imshow("image", image)
This code isn’t very exciting yet. All we are doing is importing the packages we will need, setting up an argument parser, and loading our image.
# convert the image to grayscale and create a histogram
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
cv2.imshow("gray", gray)
hist = cv2.calcHist([gray], [0], None, [256], [0, 256])
plt.figure()
plt.title("Grayscale Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
plt.plot(hist)
plt.xlim([0, 256])
Now things are getting a little more interesting. On line 2, we convert the image from the RGB colorspace to grayscale. Line 4 computes the actual histogram. Go ahead and match the arguments of the code up with the function documentation above. We can see that our first parameter is the grayscale image. A grayscale image has only one channel, hence we a use value of [0] for channels. We don’t have a mask, so we set the mask value to None. We will use 256 bins in our histogram, and the possible values range from 0 to 256.
A call to plt.show() displays:
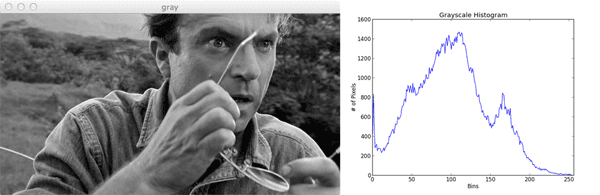
Not bad. How do we interpret this histogram? Well, the bins (0-255) are plotted on the X-axis. And the Y-axis counts the number of pixels in each bin. The majority of pixels fall in the range of ~50 to ~125. Looking at the right tail of the histogram, we see very few pixels in the range 200 to 255. This means that there are very few “white” pixels in the image.
Now that we’ve seen at a grayscale histogram, let’s look at what I call a “flattened” color histogram:
# grab the image channels, initialize the tuple of colors,
# the figure and the flattened feature vector
chans = cv2.split(image)
colors = ("b", "g", "r")
plt.figure()
plt.title("'Flattened' Color Histogram")
plt.xlabel("Bins")
plt.ylabel("# of Pixels")
features = []
# loop over the image channels
for (chan, color) in zip(chans, colors):
# create a histogram for the current channel and
# concatenate the resulting histograms for each
# channel
hist = cv2.calcHist([chan], [0], None, [256], [0, 256])
features.extend(hist)
# plot the histogram
plt.plot(hist, color = color)
plt.xlim([0, 256])
# here we are simply showing the dimensionality of the
# flattened color histogram 256 bins for each channel
# x 3 channels = 768 total values -- in practice, we would
# normally not use 256 bins for each channel, a choice
# between 32-96 bins are normally used, but this tends
# to be application dependent
print "flattened feature vector size: %d" % (np.array(features).flatten().shape)
There’s definitely more code involved in computing a flattened color histogram vs. a grayscale histogram. Let’s tear this code apart and get a better handle on what’s going on:
- Lines 29 and 30: The first thing we are going to do is split the image into its three channels: blue, green, and red. Normally, we read this is a red, green, blue (RGB). However, OpenCV stores the image as a NumPy array in reverse order: BGR. This is important to note. We then initialize a tuple of strings representing the colors.
- Lines 31-35: Here we are just setting up our PyPlot figure and initializing our list of concatenated histograms.
- Line 38: Let’s start looping over the channels.
- Line 42 and 43: We are now computing a histogram for each channel. Essentially, this is the same as computing a histogram for a single channeled grayscale image. We then concatenate the color histogram to our features list.
- Lines 46 and 47: Plot the histogram using the current channel name.
- Line 55: Here we are just examining the shape of our flattened color histogram. I call this a “flattened” histogram not because the (1) histogram has zero “peaks” or (2) I am calling NumPy’s flatten() method. I call this a “flattened” histogram because the histogram is a single list of pixel counts. Later, we explore multi-dimensional histograms (2D and 3D). A flattened histogram is simply the histogram for each individual channel concatenated together.
Now let’s plot our color histograms:
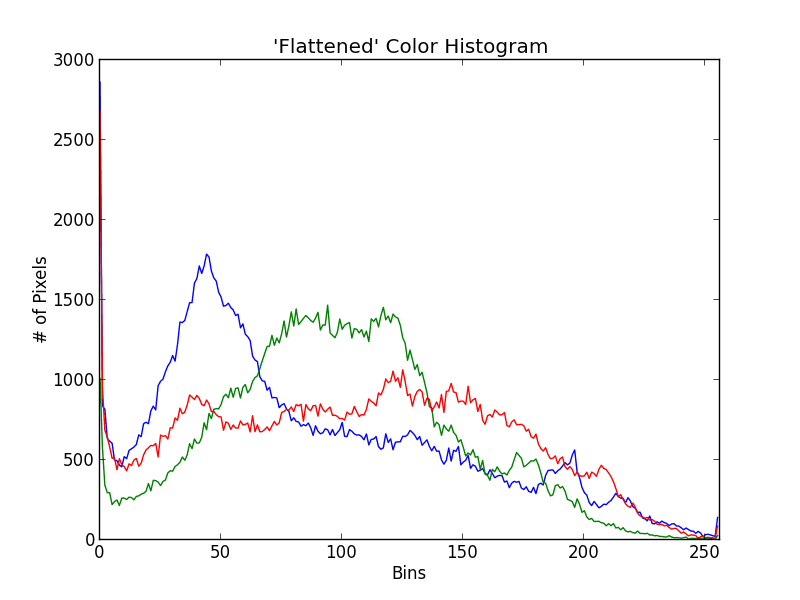
Awesome. That was pretty simple. What does this histogram tell us? Well, there is a peak in the dark blue pixel values around bin #50. This range of blue refers to Grant’s blue shirt. And the much larger range of green pixels from bin #50 to #125 refers to the forest behind Dr. Grant in the background.
Multi-dimensional Histograms
Up until this point, we have computed a histogram for only one channel at a time. Now we move on to multi-dimensional histograms and take into consideration two channels at a time.
The way I like to explain multi-dimensional histograms is to use the word AND. For example, we can ask a question such as
“how many pixels have a Red value of 10 AND a Blue value of 30?” How many pixels have a Green value of 200 AND a Red value of 130? By using the conjunctive AND we are able to construct multi-dimensional histograms.
It’s that simple. Let’s checkout some code to automate the process of building a 2D histogram:
# let's move on to 2D histograms -- I am reducing the
# number of bins in the histogram from 256 to 32 so we
# can better visualize the results
fig = plt.figure()
# plot a 2D color histogram for green and blue
ax = fig.add_subplot(131)
hist = cv2.calcHist([chans[1], chans[0]], [0, 1], None,
[32, 32], [0, 256, 0, 256])
p = ax.imshow(hist, interpolation = "nearest")
ax.set_title("2D Color Histogram for Green and Blue")
plt.colorbar(p)
# plot a 2D color histogram for green and red
ax = fig.add_subplot(132)
hist = cv2.calcHist([chans[1], chans[2]], [0, 1], None,
[32, 32], [0, 256, 0, 256])
p = ax.imshow(hist, interpolation = "nearest")
ax.set_title("2D Color Histogram for Green and Red")
plt.colorbar(p)
# plot a 2D color histogram for blue and red
ax = fig.add_subplot(133)
hist = cv2.calcHist([chans[0], chans[2]], [0, 1], None,
[32, 32], [0, 256, 0, 256])
p = ax.imshow(hist, interpolation = "nearest")
ax.set_title("2D Color Histogram for Blue and Red")
plt.colorbar(p)
# finally, let's examine the dimensionality of one of
# the 2D histograms
print "2D histogram shape: %s, with %d values" % (
hist.shape, hist.flatten().shape[0])
Yes, this is a fair amount of code. But that’s only because we are computing a 2D color histogram for each combination of RGB channels: Red and Green, Red and Blue, and Green and Blue.
Now that we are working with multi-dimensional histograms, we need to keep in mind the number of bins we are using. In previous examples, I’ve used 256 bins for demonstration purposes. However, if we used a 256 bins for each dimension in a 2D histogram, our resulting histogram would have 65,536 separate pixel counts. Not only is this wasteful of resources, it’s not practical. Most applications using somewhere between 8 and 64 bins when computing multi-dimensional histograms. As Lines 64 and 65 show, I am now using 32 bins instead of 256.
The most important take away from this code can be seen by inspecting the first arguments to the cv2.calcHist function. Here we see that we are passing in a list of two channels: the Green and Blue channels. And that’s all there is to it.
So how is a 2D histogram stored in OpenCV? It’s a 2D NumPy array. Since I used 32 bins for each channel, I now have a 32×32 histogram. We can treat this histogram as a feature vector simply by flattening it (Lines 88 and 89). Flattening our histograms yields a list with 1024 values.
How do we visualize a 2D histogram? Let’s take a look.
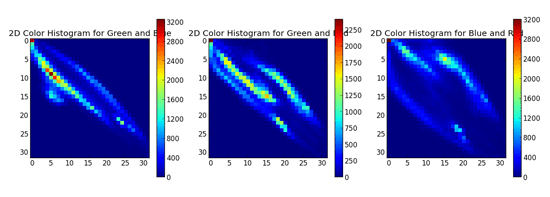
In the above Figure, we see three graphs. The first is a 2D color histogram for the Green and Blue channels, the second for Green and Red, and the third for Blue and Red. Shades of blue represent low pixel counts, whereas shades of red represent large pixel counts (i.e. peaks in the 2D histogram). We can see such a peak in the Green and Blue 2D histogram (the first graph) when X=5 and Y=10.
Using a 2D histogram takes into account two channels at a time. But what if we wanted to account for all three RGB channels? You guessed it. We’re now going to build a 3D histogram.
# our 2D histogram could only take into account 2 out # of the 3 channels in the image so now let's build a # 3D color histogram (utilizing all channels) with 8 bins # in each direction -- we can't plot the 3D histogram, but # the theory is exactly like that of a 2D histogram, so # we'll just show the shape of the histogram hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8], [0, 256, 0, 256, 0, 256]) print "3D histogram shape: %s, with %d values" % ( hist.shape, hist.flatten().shape[0])
The code here is very simple — it’s just an extension from the code above. We are now computing an 8x8x8 histogram for each of the RGB channels. We can’t visualize this histogram, but we can see that the shape is indeed (8, 8, 8) with 512 values. Again, treating the 3D histogram as a feature vector can be done by simply flattening the array.
Color Spaces
The examples in this post have only explored the RGB color space, but histograms can be constructed for any color space in OpenCV. Discussing color spaces is outside the context of this post, but if you are interested, check out the documentation on converting color spaces.
Drawbacks
Earlier in this post we made the assumption that images with similar color distributions are semantically similar. For small, simple datasets, this may in fact be true. However, in practice, this assumption does not always hold.
Let’s think about why this for.
For one, color histograms, by definition ignore both the shape and texture of the object(s) in the image. This means that color histograms have no concept of the shape of an object or the texture of the object. Furthermore, histograms also disregard any spatial information (i.e. where in the image the pixel value came from). An extension to the histogram, the color correlogram, can be used to encode a spatial relationship amongst pixels.
Let’s think about Chic Engine, my visual fashion search engine iPhone app. I have different categories for different types of clothes, such as shoes and shirts. If I were using color histograms to describe a red shoe and a red shirt, the histogram would assume they were the same object. Clearly they are both red, but the semantics end there — they are simply not the same. Color histograms simply have no way to “model” what a shoe or a shirt is.
Finally, color histograms are sensitive to “noise”, such as changes in lighting in the environment the image was captured under and quantization errors (selecting which bin to increment). Some of these limitations can potentially be mitigated by using a different color space than RGB (such as HSV or L*a*b*).
However, all that said, histograms are still widely used as image descriptors. They are dead simple to implement and very fast to compute. And while they have their limitations, they are very powerful when used correctly and in the right context.
What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Until Monday!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

I think you meant to say that the common ranges within RGB channels are [0, 255] instead of [0, 256] when describing the calcHist funtion.
Indeed, it seems I was wrong.
This used to throw me for a loop too. I’m thinking of writing a blog post about all the OpenCV and NumPy “gotchas” I’ve encountered. It’s a pretty sizeable list.
So yes, the possible pixel values for each channel in the RGB color space is [0, 255]. However, when using calcHist (and NumPy’s histogram method) the range becomes [0, 255). (Notice the parenthesis, not a bracket). It’s an extremely subtle difference, and in most cases, it wouldn’t “break” anything. But in order to capture the range [0, 255] with 256 bins, we have to specify [0, 256). It’s definitely annoying.
I had a question on line 9: ap.add_argument(“-i”, “–image”, required = True, help = “Path to the image”)
If my path is: C:\Users\Jeremy\Documents\IPython Notebooks,
would my line 9 look like ap.add_argument(“Ipython Notebooks”, “face.jpeg”, required = True, help = “Path to the image”)?
Hi Jeremy. If you are using an IPython Notebook you can skip the argument parsing entirely and use the path to your image directly. The argument parsing is only necessary if you are executing the script via command line.
I’m attempting to plot a 3D histogram. I thought it would be simple extension of the 2D examples you provide using something like:
hist = cv2.calcHist([img_patch],[0,1,2],None,[8,8,8],[0,256,0,256,0,256])
Where the Z axis would provide ‘red’ information assuming channels 0 and 1 are B and G respectively.
Not having much luck with it. Any guidance would be appreciated.
Did you have any luck with this? Seems like a useful addition!
hey, iam getting this error
iam really stucked in it…
help me out !!!
Hey Mohanish, you need to supply the
--imageswitch, which is the path to the image you want to compute a histogram for:$ python mycv_3.py --image path/to/my/image.jpgI would suggest downloading the .zip of the source code to this post which includes the example image and example command to run.
Dear Adrian,
Thank you for providing awsome material around your blog, I want to use your code to extract color histogram of images in a database, so I tried to append each of the feature list in another list as follow:
for (chan, color) in zip(chans, colors): hist = cv2.calcHist([chan], [0], None, [256], [0, 256]) features.extend(hist) Matrix.append(features)but when I write the martix as a csv file, I get a [ ] around each number in the csv file, do you have any idea how to work out this problem, as I need to read color histograms as an excel file in matlab later.
I truly appreciate your kind guidance and help.
Thank you.
Hey Hamid, have you tried looking at my guide to building image search engines? This post demonstrates how to extract color histograms from a dataset of images and then write them to a CSV file.
Hi Adrian,
When I run the code with the image you provided it get this error:
OpenCV Error: Assertion failed (size.width>0 && size.height>0) in cv::imshow, file D:\Build\OpenCV\opencv-3.1.0\modules\highgui\src\window.cpp, line 289
Seems like openCV thinks the image size is 0? Strangely it runs with .png files correctly. Any idea what might cause an error like this?
It’s a strange error, but it seems like that your system is not configured to load JPEG files. If it .png files are working correctly, then you have the proper PNG libraries installed. But I’m guessing that the JPEG libraries are not installed/are not working with OpenCV.
Hi Adrian
I wanted an equal density histogram for my research purpose. Is there some way of specifying the bins with calcHist rather than the size of the bin. I donot want equal sized bins.If the first bin is from 1 to 10 then the second may be from 11to 16 and so on.
If you’re looking for non-equal sized bins, I probably wouldn’t use the
cv2.calcHistfunction for this. Instead, the NumPy’s histogram function will give you the fine-grained control that you’re looking for.Hello, Adrian!
I have downloaded the code and ran this code but I have this error with “matplotlib import pyplot as plt” I have followed the tutorial from your blog post “Install OpenCV 3.0 and Python 2.7+ on OS X (https://www.pyimagesearch.com/2015/06/15/install-opencv-3-0-and-python-2-7-on-osx/) and installed matplotlib on the cv virtual environment.
It has this runtime error: RuntimeError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are Working with Matplotlib in a virtual enviroment see ‘Working with Matplotlib in Virtual environments’ in the Matplotlib FAQ.
I wonder how you solved this problem. Thank you for these tutorials by the way!
Hey Jooyeeon — this error happens with newer versions of matplotlib due to an incompatibly with the virtual environments. The developers are aware of the problem, but I don’t know of an exact fix for the newer versions of matplotlib. Instead, I would recommend installing a previous version of matplotlib:
$ pip install matplotlib==1.4.3This should take care of the issue.
Thanks, Adrian. It works beautifully! Can’t wait to dive into more openCV projects. I hope I can be an expert like you someday, sharing my knowledge with others to build awesome things!!
Awesome, I’m glad to hear it 🙂
I have installed 1.4.3 version but the above mentioned error is still there for me.what can i do to remove the error?
You might want to double-check which version of matplotlib you are using and whether or not you are using a Python virtual environment. Keep in mind that Python virtual environments are independent of your system Python and that you might have switched matplotlib versions for the incorrect environment.
Thank you for sharing. Nicely explained and very helpful for OpenCV beginners like me.
Fantastic, I’m happy to hear the tutorial helped Devi! 🙂
Adrian, I just wanted to tell you how thoroughly impressed I am with this blog and with your commitment to keep answering comments on (older) posts. I’ll be following along as i’m in looking to apply some CV in upcoming projects.
The threshold for following your tuts is low, yet the extra info along the way really helps build context for what we’re actually doing.
thank you so much for your effort!
Thank you for the kind words Chaidev, it’s comments like these that keep me coming back to answer comments on older posts 🙂
How to draw a histogram of an RGB image using 25 bins??
I would use
matplotlibto draw the histograms. I cover computing and extracting histograms in detail inside my book, Practical Python and OpenCV.Hi Adrian!
So Im realtively new to python and Im not able to wrap my head around the use of ‘argeparse’. ie, what is the purpose of lines 8-10? What does it do?
Hey Vishnu — I would suggest you start by reading up on the basics of command line arguments.
If anyone is getting the following error when running the code on OSX (I’m using El Capitan 10.11.5):
Terminating app due to uncaught exception ‘NSInvalidArgumentException’, reason: ‘-[NSApplication _setup:]: unrecognized selector sent to instance 0x7f81c1c85ef0’
This is what I did to resolve it:
pip install PyQT5
(at the very top of the code file)
import matplotlib
matplotlib.use(“Qt5Agg”)
I understand the problem is matplotlib relies on the OS for certain image processing/rendering functionality, and on OSX it tries to interface with the OS in an unsupported way. By specifying exactly how to interface with the OS, this problem is resolved.
Ctrl + F tags: MacOS, Apple
Thanks for sharing!
hello,i create a code page to run this code,and i copy your code.But, when it is run,it will flash and exit,can’t see any result.can you tell me why?
I would suggest you use the “Downloads” section of this tutorial to download the code for the post. Run my code, see if you get the correct result, and if so, compare the code to your own.
Hello, I also have some problems woth this one:
ap.add_argument(“-i”, “–image file/grant.jpg”, required = True, help = “Path to the image”)
the “file/grant,jpg” is the exact place I put my jpg into. And also I have tried your codes, it still doesn’t work, hope you can help me out, thanks.
You should read up on command line arguments before continuing. You DO NOT need to update the argument parsing code. The problem is that you are not supplying the command line arguments via the terminal.
Hi Adrian
I use the codes that was download by pyimagesearch,usage “python histograms.py –image grant.jpg” ,the result is just show two pictures (the raw and grayscale),I CAN’T SEE THE HISTOGRAM ,help me out .(ps. I have installed matplotlib.)
Hi Qian — I would suggest referring to this blog post on why plots may not show up.
Thanks for the great tutorial! I’ve a related question. I’m an album of photos and I want to find the brightest image in the set, or a means to generate a ‘brightness score’ for each image – 1 value which would represent an images histogram for example. I had tried cv2.calcHist but I’m struggling to pull it together into code. Any help appreciated!
Hi Richie — you’re in luck, I’ll be publishing a blog post on how to determine the “most colorful” and “least colorful” images in a dataset later this month. Be sure to keep your eye on the PyImageSearch blog!
What arguments needs to be given while running the script on terminal ?
Line 9 describes the only command line argument,
--image, that you need to supply.I am trying to use the color histogram of a image in order to subtract the background. I plan on setting all histogram bins that are not the largest value bin to zero, then inverting that mask. But I am a little unsure on how to do these manipulations in python. Any help would be appreciated!
*For context, I am taking still shots from a high altitude UAV and trying to detect targets of varying size, shape, and color.
Instead of manually doing this take a look at histogram backprojection.
So… if I grab highest values of each of the R, G, and B histograms, am I correct in thinking that will reveal the “most common” color in the image? That’s my amateur understanding: the highest peaks on the plot indicate the most pixels in that channel… combine them together as one RGB value and I find the most-found color in the image? Yes? No? More complicated than that? 🙂
That’s one way to do it but you would want to use a 3D color histogram rather than three separate single channel histograms. A better method would be to use k-means clustering to find the most dominant colors in an image. This blog post demonstrates how to do exactly that.
Hi Adrian,
It is amazing to see someone replying to every query, be it big or small. I’m new to this site, but I’m glad I found it. Feels like I’ll be getting better at computer vision.
Thank you for helping out everyone 🙂
It’s my pleasure to respond. Enjoy the blog!
hi adrian,
am doing ur 21 days crash course on computer vision & image search engine . As part of this tutorial am just gonna to learn something about image histogram via ur tutorial. after successfully installing opencv 3.4 and python 2.7 and matplotllib on my ubuntu 16.04, i got following errorwhenever am compling python script even if after changing matplotlib version manytimes…
” from matplotlib import pyplot as plt
ImportError: No module named matplotlib”
pls help me out to solve this problem as soon as possible…
thank u
Hey hashir — did you use one of my tutorials to install OpenCV? If so, make sure you use the “workon” command to access your Python virtual environment and then install matplotlib via “pip:
If you did not use a Python virtual environment you can skip the first command.
I want to know the meaning of the arguments given in the parentheses
ap.add_argument(“-i”, “–image”, required = True, help = “Path to the image”)
Make sure you read this post on command line arguments.
Hi Adrian,
Can you suggest some article regarding python implementation of color correlograms? I have studied research paper for correlogram method but didn’t find any library/method for implementing the same.
I do not have any tutorials for color correlograms. We don’t really use correlograms too often anymore. Is there a particular reason you want to use them?
I just want to have a practical view of correlograms in action and how they are better for image matching because in real world problems of image matching histogram method would likely to be failed. Localisation of histograms is an alternative but not a a general solution for different types of problems while correlograms will automatically take care of the image color localization.
That’s the thing — correlograms aren’t really “practical” anymore. The gist is that they measure co-occurrence of colors and that’s literally what makes them more achieve theoretically better accuracy than simple histograms, but at the same time, histograms are far more intuitive and easier to work with.
Hi Adrian,
I am currently working with detecting and classifying 6 types of acne (pimples in face) using OpenCV and Python to compute Color Histograms for feature extraction and classification and my algorithm is KNN.
I am successful in classifying the types of acne but I am having a problem in detecting all acne present in the face. Detecting means I want to draw BOUNDING BOX or drawing rectangles in all acne present. Do you have any idea on how I can do that?
I think the bigger question is how are you detecting acne in the first place? Do you have an existing dataset of acne that you are working with and now want to apply the method to other images?
Hello Adrian,
I am currently working on image processing project and I want to extract individual red, green and blue color pixels value from images using python. give me some guideline for that.
I would suggest following my OpenCV Tutorial to help you with that question. Additionally, you should absolutely read through Practical Python and OpenCV so you can learn the fundamentals of computer vision and image processing.
Thank You for your response. I found the answer of my question for further process i will sure go though that link. and you have done good job once again thak you.
hello sir
i just want to know that after flattening the image , what will be the channel present in the flatten image.