So you’ve extracted color histograms from a set of images…
But how are you going to compare them for similarity?
You’ll need a distance function to handle that.
But which one? How you choose? And how do you compare histograms using Python and OpenCV?
Don’t worry, I’ve got you covered.
In this blog post I’ll show you three different ways to compare histograms using Python and OpenCV, including the cv2.compareHist function.
By the end of this post you’ll be comparing histograms like a pro.
Our Example Dataset

Our example dataset consists of four images: two Doge memes, a third Doge image, but this time with added Gaussian noise, thus distorting the image, and then, velociraptors. Because I honestly can’t do a blog post without including Jurassic Park.
We’ll be using the top-left image as our “query” image in these examples. We’ll take this image and then rank our dataset for the most “similar” images, according to our histogram distance function.
Ideally, the Doge images would appear in the top three results, indicating that they are more “similar” to the query, with the photo of the raptors placed at the bottom, since it is least semantically relevant.
However, as we’ll find out, the addition of Gaussian noise to the bottom-left Doge image can throw off our histogram comparison methods. Choosing which histogram comparison function to use is normally dependent on (1) the size of the dataset (2) as well as quality of the images in your dataset — you’ll definitely want to perform some experiments and explore different distance functions to get a feel for what metric will work best for your application.
With all that said, let’s have Doge teach us about comparing histograms.
Much histogram. Wow. I OpenCV. A lot computer vision, indeed.
3 Ways to Compare Histograms Using OpenCV and Python
# import the necessary packages
from scipy.spatial import distance as dist
import matplotlib.pyplot as plt
import numpy as np
import argparse
import glob
import cv2
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required = True,
help = "Path to the directory of images")
args = vars(ap.parse_args())
# initialize the index dictionary to store the image name
# and corresponding histograms and the images dictionary
# to store the images themselves
index = {}
images = {}
The first thing we are going to do is import our necessary packages on Lines 2-7. The distance sub-package of SciPy contains implementations of many distance functions, so we’ll import it with an alias of dist to make our code more clean.
We’ll also be using matplotlib to display our results, NumPy for some numerical processing, argparse to parse command line arguments, glob to grab the paths to our image dataset, and cv2 for our OpenCV bindings.
Then, Lines 10-13 handle parsing our command line arguments. We only need a single switch, --dataset, which is the path to the directory containing our image dataset.
Finally, on Lines 18 and 19, we initialize two dictionaries. The first is index, which stores our color histograms extracted from our dataset, with the filename (assumed to be unique) as the key, and the histogram as the value.
The second dictionary is images, which stores the actual images themselves. We’ll make use of this dictionary when displaying our comparison results.
Now, before we can start comparing histograms, we first need to extract the histograms from our dataset:
# loop over the image paths
for imagePath in glob.glob(args["dataset"] + "/*.png"):
# extract the image filename (assumed to be unique) and
# load the image, updating the images dictionary
filename = imagePath[imagePath.rfind("/") + 1:]
image = cv2.imread(imagePath)
images[filename] = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# extract a 3D RGB color histogram from the image,
# using 8 bins per channel, normalize, and update
# the index
hist = cv2.calcHist([image], [0, 1, 2], None, [8, 8, 8],
[0, 256, 0, 256, 0, 256])
hist = cv2.normalize(hist, hist).flatten()
index[filename] = hist
First, we utilize glob to grab our image paths and start looping over them on Line 22.
Then, we extract the filename from the path, load the image, and then store the image in our images dictionary on Lines 25-27.
Remember, by default, OpenCV stores images in BGR format rather than RGB. However, we’ll be using matplotlib to display our results, and matplotlib assumes the image is in RGB format. To remedy this, a simple call to cv2.cvtColor is made on Line 27 to convert the image from BGR to RGB.
Computing the color histogram is handled on Line 32. We’ll be extracting a 3D RGB color histogram with 8 bins per channel, yielding a 512-dim feature vector once flattened. The histogram is normalized on Line 34 and finally stored in our index dictionary on Line 35.
For more details on the cv2.calcHist function, definitely take a look at my guide to utilizing color histograms for computer vision and image search engines post.
Now that we have computed histograms for each of our images, let’s try to compare them.
Method #1: Using the OpenCV cv2.compareHist function
Perhaps not surprisingly, OpenCV has a built in method to facilitate an easy comparison of histograms: cv2.compareHist. Check out the function signature below:
cv2.compareHist(H1, H2, method)
The cv2.compareHist function takes three arguments: H1, which is the first histogram to be compared, H2, the second histogram to be compared, and method, which is a flag indicating which comparison method should be performed.
The method flag can be any of the following:
-
cv2.HISTCMP_CORREL: Computes the correlation between the two histograms.cv2.HISTCMP_CHISQR: Applies the Chi-Squared distance to the histograms.cv2.HISTCMP_INTERSECT: Calculates the intersection between two histograms.cv2.HISTCMP_BHATTACHARYYA: Bhattacharyya distance, used to measure the “overlap” between the two histograms.
Now it’s time to apply the cv2.compareHist function to compare our color histograms:
# METHOD #1: UTILIZING OPENCV
# initialize OpenCV methods for histogram comparison
OPENCV_METHODS = (
("Correlation", cv2.HISTCMP_CORREL),
("Chi-Squared", cv2.HISTCMP_CHISQR),
("Intersection", cv2.HISTCMP_INTERSECT),
("Hellinger", cv2.HISTCMP_BHATTACHARYYA))
# loop over the comparison methods
for (methodName, method) in OPENCV_METHODS:
# initialize the results dictionary and the sort
# direction
results = {}
reverse = False
# if we are using the correlation or intersection
# method, then sort the results in reverse order
if methodName in ("Correlation", "Intersection"):
reverse = True
Lines 39-43 define our tuple of OpenCV histogram comparison methods. We’ll be exploring the Correlation, Chi-Squared, Intersection, and Hellinger/Bhattacharyya methods.
We start looping over these methods on Line 46.
Then, we define our results dictionary on Line 49, using the filename of the image as the key and its similarity score as the value.
I would like to draw special attention to Lines 50-55. We start by initializing a reverse variable to False. This variable handles how sorting the results dictionary will be performed. For some similarity functions a LARGER value indicates higher similarity (Correlation and Intersection). And for others, a SMALLER value indicates higher similarity (Chi-Squared and Hellinger).
Thus, we need to make a check on Line 54. If our distance method is Correlation or Intersection, our results should be sorted in reverse order.
Now, lets compare our histograms:
# loop over the index for (k, hist) in index.items(): # compute the distance between the two histograms # using the method and update the results dictionary d = cv2.compareHist(index["doge.png"], hist, method) results[k] = d # sort the results results = sorted([(v, k) for (k, v) in results.items()], reverse = reverse)
We start by looping over our index dictionary on Line 58.
Then we compare the color histogram to our Doge query image (see the top-left image in Figure 1 above) to the current color histogram in the index dictionary on Line 61. The results dictionary is then updated with the distance value.
Finally, we sort our results in the appropriate order on Line 65.
Now, lets move on to displaying our results:
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: %s" % (methodName))
fig.suptitle(methodName, fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the OpenCV methods
plt.show()
We start off by creating our query figure on Lines 68-71. This figure simply displays our Doge query image for reference purposes.
Then, we create a figure for each of our OpenCV histogram comparison methods on Line 74-83. This code is fairly self-explanatory. All we are doing is looping over the results on Line 78 and adding the image associated with the current result to our figure on Line 82.
Finally, Line 86 then displays our figures.
When executed, you should see the following results:
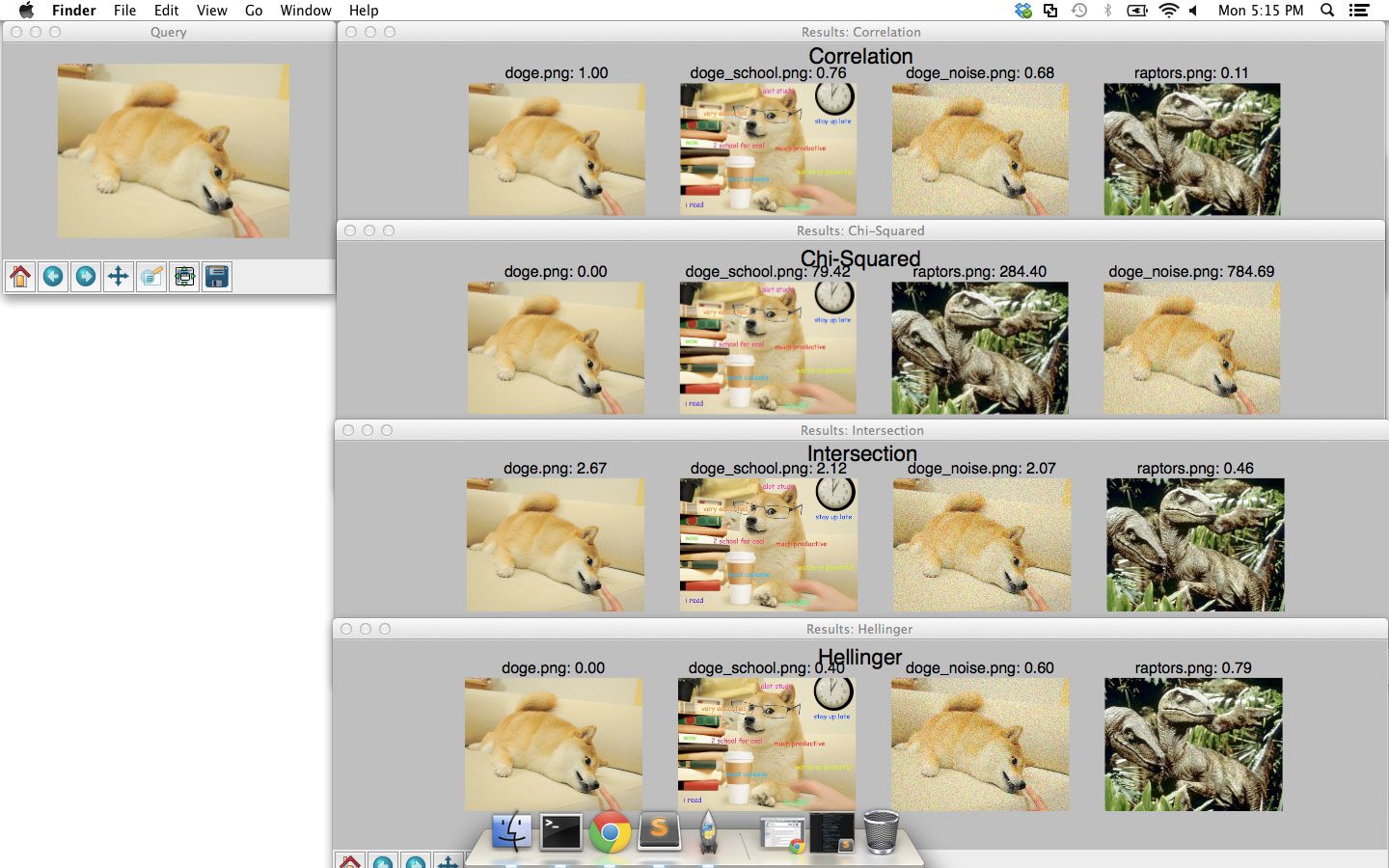
cv2.compareHist function.The image on the left is our original Doge query. The figures on the right contain our results, ranked using the Correlation, Chi-Squared, Intersection, and Hellinger distances, respectively.
For each distance metric, our the original Doge image is placed in the #1 result position — this makes sense because we are using an image already in our dataset as a query. We expect this image to be in the #1 result position since the image is identical to itself. If this image was not in the #1 result position, then we would know there is likely a bug somewhere in our code!
We then see the Doge school meme is in the second result position for all distance metrics.
However, adding Gaussian noise to the original Doge image can hurt performance. The Chi-Squared distance seems especially sensitive.
Does this mean that the Chi-Squared metric should not be used?
Absolutely not!
In reality, the similarity function you use is entirely dependent on your dataset and what the goals of your application. You will need to run some experiments to determine the optimally performing metric.
Next up, let’s explore some SciPy distance functions.
Method #2: Using the SciPy distance metrics
The main difference between using SciPy distance functions and OpenCV methods is that the methods in OpenCV are histogram specific. This is not the case for SciPy, which implements much more general distance functions. However, they are still important to note and you can likely make use of them in your own applications.
Let’s check out the code:
# METHOD #2: UTILIZING SCIPY
# initialize the scipy methods to compaute distances
SCIPY_METHODS = (
("Euclidean", dist.euclidean),
("Manhattan", dist.cityblock),
("Chebysev", dist.chebyshev))
# loop over the comparison methods
for (methodName, method) in SCIPY_METHODS:
# initialize the dictionary dictionary
results = {}
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the method and update the results dictionary
d = method(index["doge.png"], hist)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()])
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: %s" % (methodName))
fig.suptitle(methodName, fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the SciPy methods
plt.show()
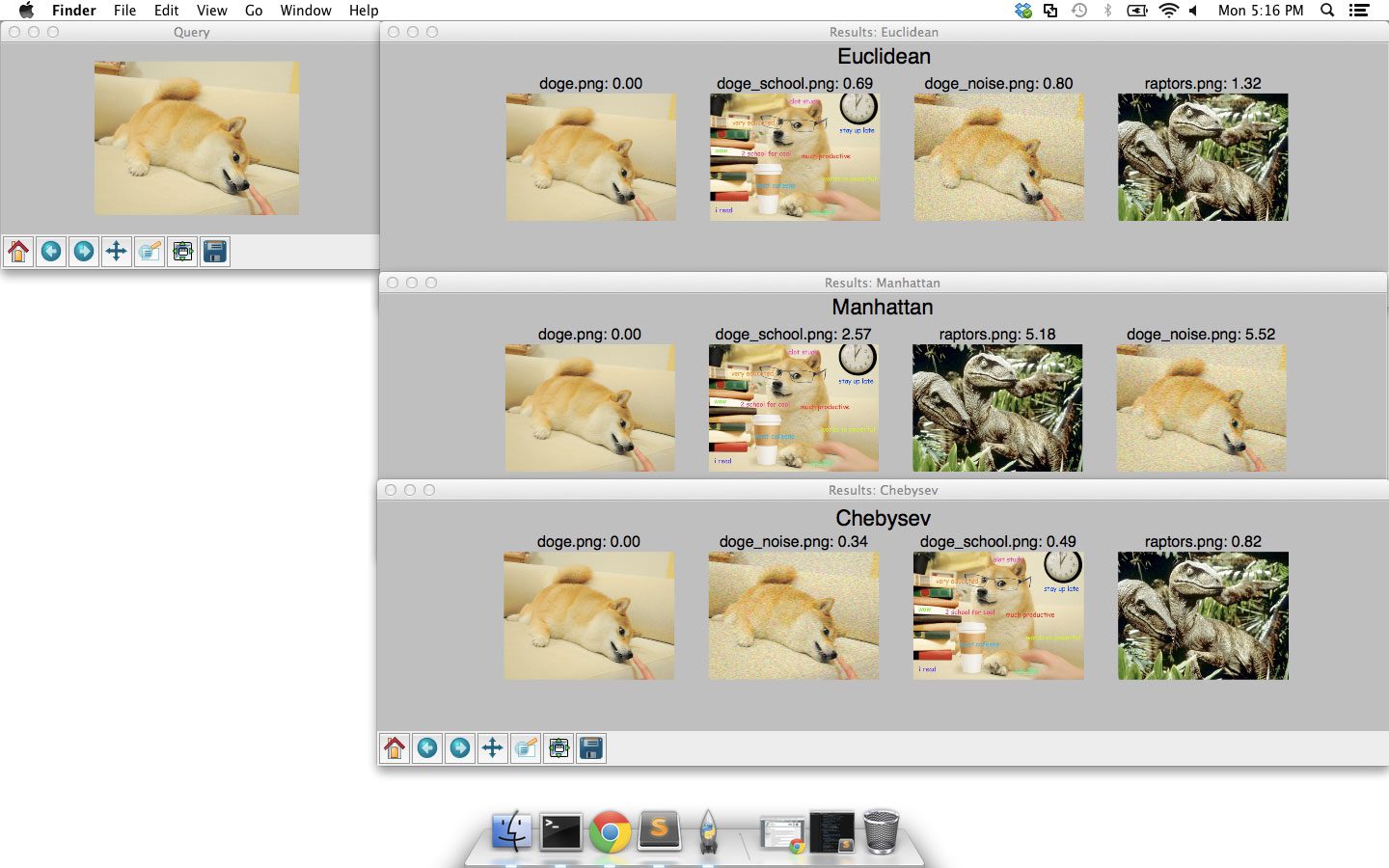
On Lines 90-93 we define tuples containing the SciPy distance functions we are going to explore.
Specifically, we’ll be using the Euclidean distance, Manhattan (also called City block) distance, and the Chebyshev distance.
From there, our code is pretty much identical to the OpenCV example above.
We loop over the distance functions on Line 96, perform the ranking on Lines 101-108, and then present the results using matplotlib on Lines 111-129.
The figure below shows our results:
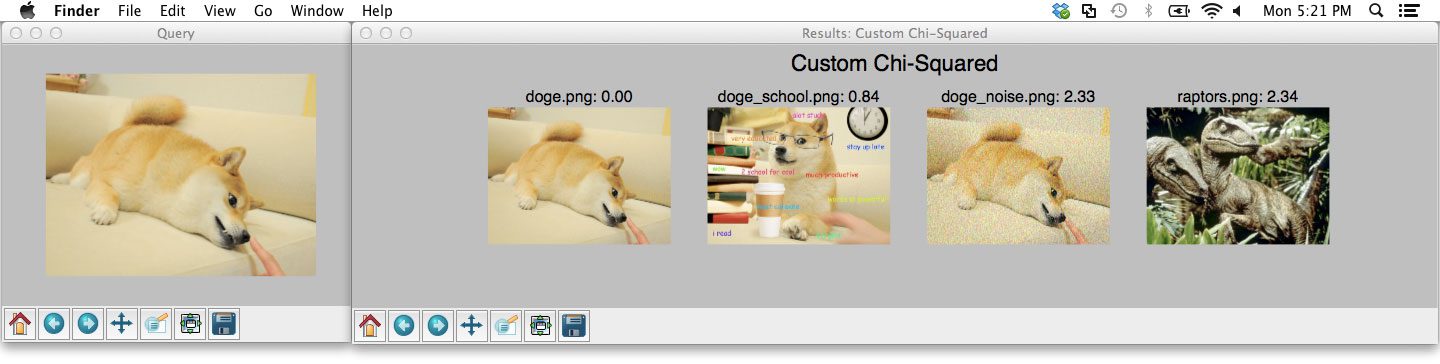
Method #3: Roll-your-own similarity measure
The third method to compare histograms is to “roll-your-own” similarity measure. I define my own Chi-Squared distance function below:
# METHOD #3: ROLL YOUR OWN def chi2_distance(histA, histB, eps = 1e-10): # compute the chi-squared distance d = 0.5 * np.sum([((a - b) ** 2) / (a + b + eps) for (a, b) in zip(histA, histB)]) # return the chi-squared distance return d
And you may be thinking, hey, isn’t the Chi-Squared distance already implemented in OpenCV?
Yes. It is.
But the OpenCV implementation only takes the squared difference of each individual bin, divided by the bin count for the first histogram.
In my implementation, I take the squared difference of each bin count, divided by the sum of the bin count values, implying that large differences in the bins should contribute less weight.
From here, we can apply my custom Chi-Squared function to the images:
# initialize the results dictionary
results = {}
# loop over the index
for (k, hist) in index.items():
# compute the distance between the two histograms
# using the custom chi-squared method, then update
# the results dictionary
d = chi2_distance(index["doge.png"], hist)
results[k] = d
# sort the results
results = sorted([(v, k) for (k, v) in results.items()])
# show the query image
fig = plt.figure("Query")
ax = fig.add_subplot(1, 1, 1)
ax.imshow(images["doge.png"])
plt.axis("off")
# initialize the results figure
fig = plt.figure("Results: Custom Chi-Squared")
fig.suptitle("Custom Chi-Squared", fontsize = 20)
# loop over the results
for (i, (v, k)) in enumerate(results):
# show the result
ax = fig.add_subplot(1, len(images), i + 1)
ax.set_title("%s: %.2f" % (k, v))
plt.imshow(images[k])
plt.axis("off")
# show the custom method
plt.show()
This code should start to feel pretty standard now.
We loop over the index and rank the results on Lines 144-152. Then we present the results on Lines 155-173.
Below is the output of using my custom Chi-Squared function:
Take a second to compare Figure 4 to Figure 2 above. Specifically, examine the OpenCV Chi-Squared results versus my custom Chi-Squared function — the Doge image with noise added is now in the third result position rather than the fourth.
Does this mean you should use my implementation over the OpenCV one?
No, not really.
In reality, my implementation will be much slower than the OpenCV one, simply because OpenCV is compiled C/C++ code, which will be faster than Python.
But if you need to roll-your-own distance function, this is the best way to go.
Just make sure that you take the time to perform some experiments and see which distance function is right for your application.
What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post I showed you three ways to compare histograms using Python and OpenCV.
The first way is to use the built in cv2.compareHist function of OpenCV. The benefits of this function is that it’s extremely fast. Remember, OpenCV is compiled C/C++ code and your performance gains will be very high versus standard, vanilla Python.
The second benefit is that this function implements four distance methods that are geared towards comparing histograms, including Correlation, Chi-Squared, Intersection, and Bhattacharyya/Hellinger.
However, you are limited by these functions. If you want to customize the distance function, you’ll have to implement your own.
The second way to compare histograms using OpenCV and Python is to utilize a distance metric included in the distance sub-package of SciPy.
However, if the above two methods aren’t what you are looking for, you’ll have to move onto option three and “roll-your-own” distance function by implementing it by hand.
Hopefully this helps you with your histogram comparison needs using OpenCV and Python!
Feel free to leave a comment below or shoot me an email if you want to chat more about histogram comparison methods.
And be sure to signup for the newsletter below to receive awesome, exclusive content that I don’t publish on this blog!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

