This is a guest post by Michael Herman from Real Python – learn Python programming and web development through hands-on, interesting examples that are useful and fun!
In this tutorial, we’ll take the command line image search engine from the previous tutorial and turn it into a full-blown web application using Python and Flask. More specifically, we’ll be creating a Single Page Application (SPA) that consumes data via AJAX (on the front-end) from an internal, REST-like API via Python/Flask (on the back-end).
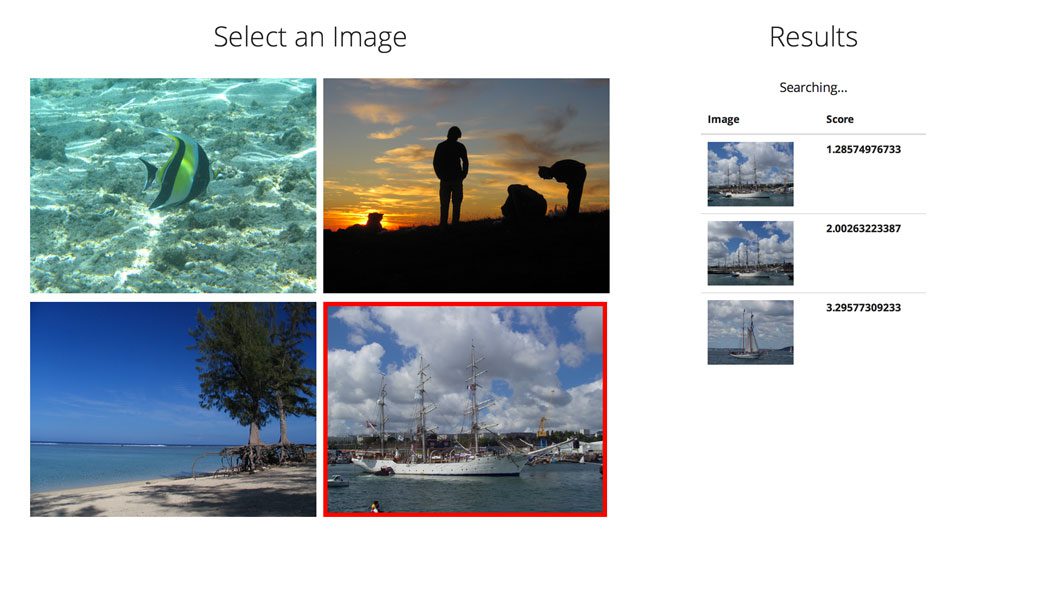
The end product will look like this:
New to Flask? Start with the official Quickstart guide or the “Flask: QuickStart” chapter in the second Real Python course.
Setup
You can setup you development either with or without Docker.
With Docker:
If you don’t have Docker installed, follow the official Docker documentation to install both Docker and boot2docker. Then with boot2docker up and running, run docker version to test the Docker installation.
Create a directory to house your project “flask-image-search”.
Grab the _setup.zip from the repository, unzip the files, and add them to your project directory.
Now build the Docker image:
$ docker build --rm -t opencv-docker .
Once built, run the Docker container:
$ docker run -p 80:5000 opencv-docker
Open your web browser and navigate to the IP address associated with the DOCKER_HOST variable – which should be http://192.168.59.103/; if not, run boot2docker ip to get the correct address – you should see the text “Welcome!” in your browser.
Without Docker:
Create a directory to house your project “flask-image-search”.
Grab the _setup.zip from the repository, unzip the files, and add them to your project directory. Create and activate a virtualenv, then install the requirements via Pip:
$ pip install flask numpy scipy matplotlib scikit-image gunicorn $ pip freeze > requirements.txt
Basics
Since you’ve already built the search engine, we just need to transfer the relevant code to Flask. Essentially, we’re just going to wrap the image search engine in Flask.
Right now your project directory should look like this:
├── Dockerfile ├── app │ ├── app.py │ ├── index.csv │ ├── pyimagesearch │ │ ├── __init__.py │ │ ├── colordescriptor.py │ │ └── searcher.py │ ├── static │ │ ├── main.css │ │ └── main.js │ └── templates │ ├── _base.html │ └── index.html ├── config │ ├── app.ini │ ├── nginx.conf │ └── supervisor.conf └── requirements.txt
The Dockerfile and the files with the “config” directory are used specifically to get our app up an running in the Docker container (if you used Docker, of course). Don’t worry too much about how these work, but if you are curious you can reference the inline comments in the Dockerfile. Within the “app” directory the index.csv file as well as the files within the “pyimagesearch” directory are specific to, well, the image search engine. Reference the previous tutorial for more information.
Now, let’s take a closer look at the files and folders within the “app” directory that are specific to Flask:
- The app.py file is our Flask application. Be sure to reference the inline comments within the file to fully understand what’s happening. It’s important to note that in most cases you should break your app into smaller pieces. However, since this app (as well as our finished app) are small, we can get away with storing all the functionality in a single file.
- The “static” directory houses static files, like – stylesheets, JavaScript files, images, etc.
- The “templates” directory houses our app’s templates. Take a look at the relationship between the _base.html and index.html templates. This is called template inheritance. For more on this, check out this blog post.
That’s it for our current project structure. With that, let’s start building!
Workflow
Put simply, we’ll focus on two routes/endpoints:
- The main route (‘/’): This route handles the main user interaction. Users can select an image (which sends a POST request to the search route) and then displays the similar images.
- The search route (‘/search’): This route handles POST requests. It will take an image (name) and then using the majority of the search engine code return similar images (URLs).
Back-end
Main Route
The back-end code is already set up. That’s right – We just need to render a template when a user requests / . We do however, need to update the template, index.html, as well as add HTML, CSS, and Javascript/jQuery code. This will be handled in the Front-end section.
Search Route
Again, this route is meant to:
- Handle POST requests,
- Take an image and search for similar images (using the already completed search engine code), and
- Return the similar images (in the form of URLs) in JSON format
Add the following code to app.py, just below the main route.
# search route
@app.route('/search', methods=['POST'])
def search():
if request.method == "POST":
RESULTS_ARRAY = []
# get url
image_url = request.form.get('img')
try:
# initialize the image descriptor
cd = ColorDescriptor((8, 12, 3))
# load the query image and describe it
from skimage import io
import cv2
query = io.imread(image_url)
query = (query * 255).astype("uint8")
(r, g, b) = cv2.split(query)
query = cv2.merge([b, g, r])
features = cd.describe(query)
# perform the search
searcher = Searcher(INDEX)
results = searcher.search(features)
# loop over the results, displaying the score and image name
for (score, resultID) in results:
RESULTS_ARRAY.append(
{"image": str(resultID), "score": str(score)})
# return success
return jsonify(results=(RESULTS_ARRAY[:3]))
except:
# return error
jsonify({"sorry": "Sorry, no results! Please try again."}), 500
What’s happening?
- We define the endpoint,
/search', along with the allowed HTTP request methods,methods=['POST']. Jump back to the/main endpoint real quick. Notice how we did not specify the allowed request methods. Why? That’s because by default all endpoints respond to GET requests. - We grab the image,
image_url = request.form.get('img')and then using a try/except we search for similar images. - Compare the loop in the above code, to the loop in search.py from the previous tutorial. Here, instead of outputting the results, we’re simply grabbing them and adding them to a list. This list is then passed into a special Flask function called
jsonifywhich returns a JSON response.
Be sure to update the imports-
import os from flask import Flask, render_template, request, jsonify from pyimagesearch.colordescriptor import ColorDescriptor from pyimagesearch.searcher import Searcher
-and add the following variable, just below the creation of the Flask instance, which specifies the path to the index.csv file used in the image search-
INDEX = os.path.join(os.path.dirname(__file__), 'index.csv')
We’ll look at the exact output of this in the next section.
Front-end
So, with our back-end code done, we just need to update the structure and feel (via HTML and CSS) as well as add user interaction (via JavaScript/jQuery). To help with this, we’ll use the Bootstrap front-end framework.
Open the _base.html template.
We’ve already included the Bootstrap stylesheet (via a CDN) along with the jQuery and Bootstrap JavaScript libraries and a custom stylesheet and JavaScript file (both of which reside in the “static” folder):
<!-- stylesheets -->
<link href="//maxcdn.bootstrapcdn.com/bootswatch/3.2.0/yeti/bootstrap.min.css" rel="stylesheet" media="screen">
<link href="{{ url_for('static', filename='main.css') }}" rel="stylesheet">
... snip ...
<!-- Scripts -->
<script src="//code.jquery.com/jquery-2.1.1.min.js" type="text/javascript"></script>
<script src="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/js/bootstrap.min.js" type="text/javascript"></script>
<script src="{{ url_for('static', filename='main.js') }}" type="text/javascript"></script>
Template
First, let’s update the index.html template:
{% extends "_base.html" %}
{% block content %}
<div class="row">
<div class="col-md-7">
<h2>Select an Image</h2>
<br>
<div class="row">
<div class="col-md-6">
<p><img src="https://static.hcl.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/103100.png" style="height: 250px;" class="img"></p>
<p><img src="https://static.hcl.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/103300.png" style="height: 250px;" class="img"></p>
</div>
<div class="col-md-6">
<p><img src="https://static.hcl.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/127502.png" style="height: 250px;" class="img"></p>
<p><img src="https://static.hcl.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/queries/123600.png" style="height: 250px;" class="img"></p>
</div>
</div>
</div>
<div class="col-md-3 col-md-offset-1">
<h2>Results</h2>
<br>
<table class="table" id="results-table">
<thead>b
<tr>
<th>Image</th>
<th>Score</th>
</tr>
</thead>
<tbody id="results">
</tbody>
</table>
</div>
</div>
<br>
{% endblock %}
Now let’s test…
With Docker:
Rebuild the Docker image and then run the new container:
$ docker build --rm -t opencv-docker . $ docker run -p 80:5000 opencv-docker
Without Docker:
$ python app/app.py
Navigate to your app in the browser, and you should see:

As you can tell, we added four images on the left side and a results table on the right side. Pay attention to the CSS selectors (id s and class es) in the above HTML code. The row and col-md-x classes are associated with the Bootstrap grid system. The remaining id s and class es are used for adding styles with CSS and/or interaction via JavaScript/jQuery.
JavaScript/jQuery
Note: If you’re unfamiliar with JavaScript and jQuery basics, please check out the Madlibs tutorial.
Let’s break down the user interaction by each individual piece of interaction.
Image Click
The interaction begins with an image click. In other words, the end user clicks one of the four images on the left side of the page with the end goal of finding similar images.
Update the main.js file:
// ----- custom js ----- //
$(function() {
// sanity check
console.log( "ready!" );
// image click
$(".img").click(function() {
// add active class to clicked picture
$(this).addClass("active")
// grab image url
var image = $(this).attr("src")
console.log(image)
});
});
Run your app. Either:
- Rebuild the Docker image, and run the new container.
- Run
python app/app.py
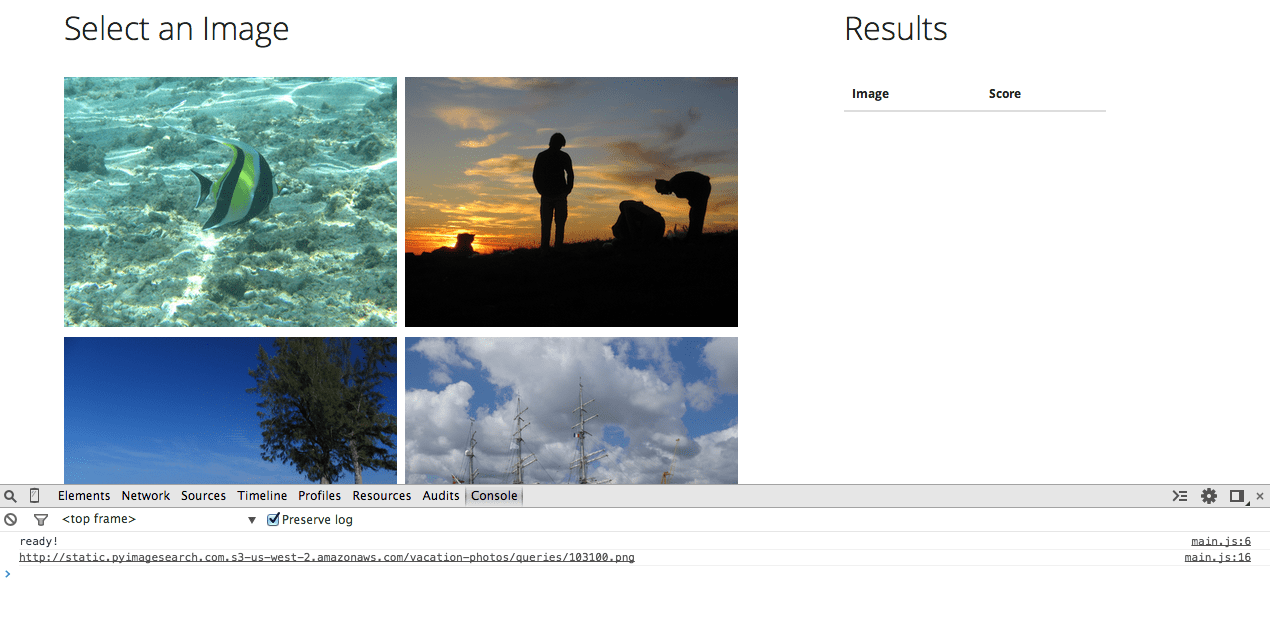
Then navigate to your app in the browser. Open your JavaScript console and then click one of the images. You should see:
 So, the jQuery code handles the click event by grabbing the URL of the specific image clicked and adding a CSS class (which we still need to add to the CSS file). The link between the jQuery code and the HTML is the
So, the jQuery code handles the click event by grabbing the URL of the specific image clicked and adding a CSS class (which we still need to add to the CSS file). The link between the jQuery code and the HTML is the img class – $(".img").click(function() and class="img" , respectively. This should be clear.
AJAX Request
With the image URL in hand, we can now send it to the back-end via an AJAX request, which is a client-side technology for making asynchronous requests that don’t cause an entire page refresh. Most SPAs use some sort of asynchronous technology to prevent a page refresh when requesting data since this enhances the overall user experience.
Update main.js like so:
// ----- custom js ----- //
$(function() {
// sanity check
console.log( "ready!" );
// image click
$(".img").click(function() {
// add active class to clicked picture
$(this).addClass("active")
// grab image url
var image = $(this).attr("src")
console.log(image)
// ajax request
$.ajax({
type: "POST",
url: "/search",
data : { img : image },
// handle success
success: function(result) {
console.log(result.results);
},
// handle error
error: function(error) {
console.log(error);
}
});
});
});
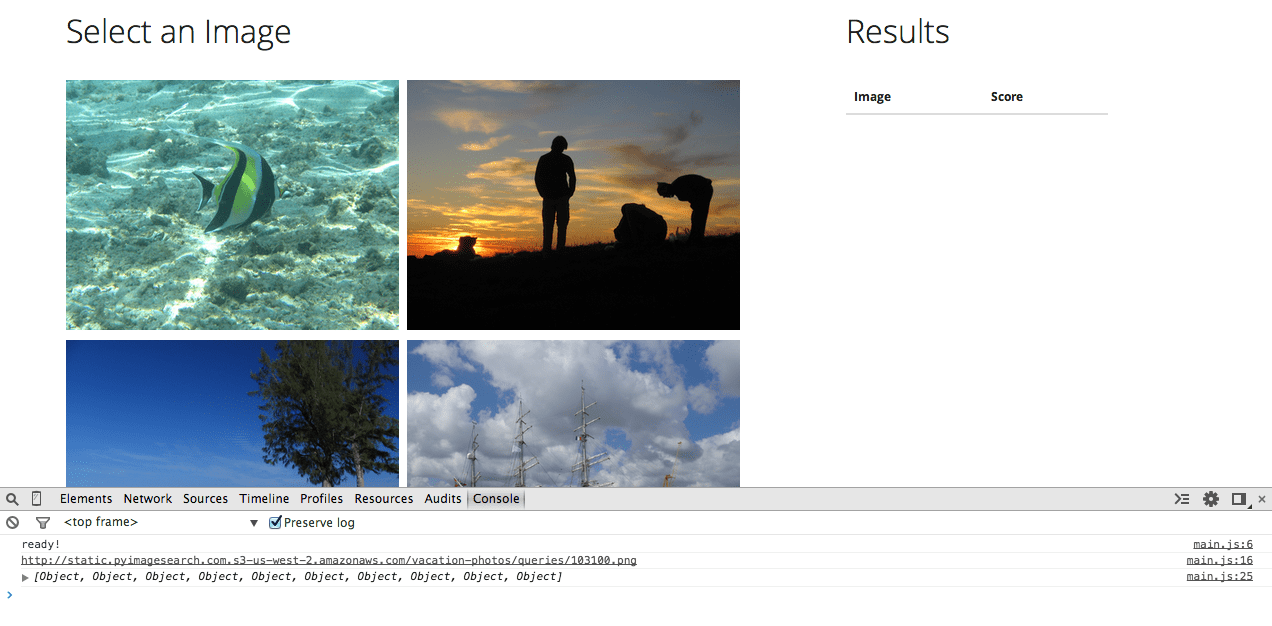
You know the drill: Run the app, and then refresh your browser. Click an image again, and then after a few seconds you should see:
 Note: This request is quite slow since we are searching a CSV rather than an actual database – i.e., SQLite, Postgres, MySQL. It’s a fairly trivial job to convert the data to a database. Try this on your own. Feel free to comment below if you have questions and/or a solution that you’d like us to look at. Cheers!
Note: This request is quite slow since we are searching a CSV rather than an actual database – i.e., SQLite, Postgres, MySQL. It’s a fairly trivial job to convert the data to a database. Try this on your own. Feel free to comment below if you have questions and/or a solution that you’d like us to look at. Cheers!
This time after the user click, we send a POST request to the /search endpoint, which includes the image URL. The back-end does it’s magic (grabbing the image, running the search code) and then returns the results in JSON format. The AJAX request has two handlers – one for a success and one for a failure. Jumping back to the back-end, the /search route either returns a 200 response (a success) or a 500 response (a failure) along with the data or an error message:
# return success
return jsonify(results=(RESULTS_ARRAY[::-1]))
except:
# return error
jsonify({"sorry": "Sorry, no results! Please try again."}), 500
Back to the front-end… since the result was successful, you can see the data in the JavaScript console:
[Object, Object, Object, Object, Object, Object, Object, Object, Object, Object]
This is just an array of JSON objects. Go ahead and expand the array and open an individual object:
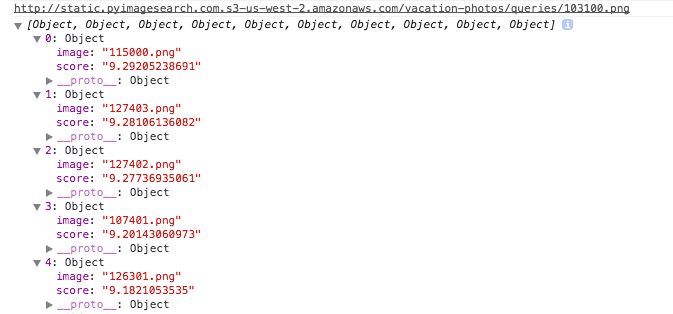 So, each object has an image and a score that represents the “similarity” between the query image and the result image. The smaller the score is, the more “similar” the query is to the result. A similarity of zero would indicate “perfect similarity”. This is the exact data we want to present to the end user.
So, each object has an image and a score that represents the “similarity” between the query image and the result image. The smaller the score is, the more “similar” the query is to the result. A similarity of zero would indicate “perfect similarity”. This is the exact data we want to present to the end user.
Update the DOM
We’re in the home stretch! Let’s update the success and error handlers so that once one of them receives data from the back-end, we append that data to the DOM:
<a href="'+url+data[i][" data-mce-href="'+url+data[i][">'+data[i]["image"]+'</a>'+data[i]['score']+'') }; }, // handle error error: function(error) { console.log(error); // show error $("#error").show(); }" >// handle success
success: function(result) {
console.log(result.results);
var data = result.results
// loop through results, append to dom
for (i = 0; i < data.length; i++) {
$("#results").append('<tr><th><a href="'+url+data[i]["image"]+'">'+data[i]["image"]+'</a></th><th>'+data[i]['score']+'</th></tr>')
};
},
// handle error
error: function(error) {
console.log(error);
// show error
$("#error").show();
}
In the success handler, we loop through the results, add in some HTML (for the table), then append the data to an id of results (which is already part of the HTML template). The error handler does not actually update the DOM with the exact error returned. Instead, we log the exact error it to the console, for us to see, and then “unhide” an HTML element with an id of error (which, again, we need to add to the HTML template).
We also need to add some global variables to the top of the file JavaScript file:
// ----- custom js ----- // // global var url = 'http://static.hcl.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/dataset/'; var data = []; ... snip ...
Look through the file and see if you can find how these variables are put to use.
Finally, before we test, let’s update the index.html template…
Add:
<p id="error">Oh no! No results! Check your internet connection.</p>
Right above:
<table class="table" id="results-table">
Okay. Think about what’s going to happen now when we test. if all went well, you should see:

Boom! You can even click on the image URLs to see the actual results (e.g., the similar images). Notice how you can see the error though. We still have some cleaning up to do.
DOM Cleanup
With the main functionality done, we just need to do a bit of housekeeping. Update main.js like so:
// ----- custom js ----- //
// hide initial
$("#searching").hide();
$("#results-table").hide();
$("#error").hide();
// global
var url = 'http://static.hcl.pyimagesearch.com.s3-us-west-2.amazonaws.com/vacation-photos/dataset/';
var data = [];
$(function() {
// sanity check
console.log( "ready!" );
// image click
$(".img").click(function() {
// empty/hide results
$("#results").empty();
$("#results-table").hide();
$("#error").hide();
// add active class to clicked picture
$(this).addClass("active")
// grab image url
var image = $(this).attr("src")
console.log(image)
// show searching text
$("#searching").show();
console.log("searching...")
// ajax request
$.ajax({
type: "POST",
url: "/search",
data : { img : image },
// handle success
success: function(result) {
console.log(result.results);
var data = result.results
// loop through results, append to dom
for (i = 0; i < data.length; i++) {
$("#results").append('<tr><th><a href="'+url+data[i]["image"]+'">'+data[i]["image"]+'</a></th><th>'+data[i]['score']+'</th></tr>')
};
},
// handle error
error: function(error) {
console.log(error);
// append to dom
$("#error").append()
}
});
});
});
Take a look at the added code…
// hide initial
$("#searching").hide();
$("#results-table").hide();
$("#error").hide();
and
// empty/hide results
$("#results").empty();
$("#results-table").hide();
$("#error").hide();
and
// remove active class
$(".img").removeClass("active")
and
// show searching text
$("#searching").show();
console.log("searching...")
and
// show table
$("#results-table").show();
We’re just hiding and showing different HTML elements based on the user interaction and whether the results of the AJAX request is a success or failure. If you’re really paying attention you probably saw that there is a new CSS selector that you have not seen before – #searching . What does this mean? Well, first off we need to update the template…
Add:
<p id="searching">Searching...</p>
Right above:
<p id="error">Oh no! No results! Check your internet connection.</p>
Now, let’s test! What’s different? Well, when the end user clicks an image, the text Searching... appears, which disappears when results are added. Then if the user clicks another image, the previous results disappear, the Searching... text reappears, and finally the new results are added to the DOM.
Take a breath. Or two. We’re now done with the JavaScript portion. It’s a good idea to review this before moving on.
CSS
There’s a lot we could do, style-wise, but let’s keep it simple. Add the following code to main.css:
.center-container {
text-align: center;
padding-top: 20px;
padding-bottom: 20px;
}
.active {
border: 5px solid red;
}
Run the app, which should now look like this:
 The big change is now when a user clicks an image, a red border appears around it, just reminding the end user which image s/he clicked. Try clicking another image. The red border should now appear around that image. Return to the JavaScript file and review the code to find out how this works.
The big change is now when a user clicks an image, a red border appears around it, just reminding the end user which image s/he clicked. Try clicking another image. The red border should now appear around that image. Return to the JavaScript file and review the code to find out how this works.
Refactor
We could stop here, but let’s refactor the code slightly to show thumbnails of the top three results. This is an image search engine, after all – We should display some actual images!
Starting with the back-end, update the search() view function so that it returns only the top three results:
return jsonify(results=(RESULTS_ARRAY[::-1][:3]))
Next update the for loop within the success handler main.js:
// loop through results, append to dom
for (i = 0; i < data.length; i++) {
$("#results").append('<tr><th><a href="'+url+data[i]["image"]+'"><img src="'+url+data[i]["image"]+
'" class="result-img"></a></th><th>'+data[i]['score']+'</th></tr>')
};
Finally, add the following CSS style:
.result-img {
max-width: 100px;
max-height: 100px;
}
You should now have:
Boom!
What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Conclusion and Next steps
To recap, we took the search engine code from the first tutorial and wrapped in in Flask to create a full-featured web application. If you’d like to continue working with Flask and web development in general, try:
- Replacing the static CSV file with a relational database;
- Updating the overall user experience by allowing a user to upload an image, rather than limiting the user to search only by the four images;
- Adding unit and integration tests;
- Deploying to Heroku.
Be sure to check out the Real Python course to learn how to do all of these and more.
Cheers!

Join the PyImageSearch Newsletter and Grab My FREE 17-page Resource Guide PDF
Enter your email address below to join the PyImageSearch Newsletter and download my FREE 17-page Resource Guide PDF on Computer Vision, OpenCV, and Deep Learning.

