
Between myself and my father, Jemma, the super-sweet, hyper-active, extra-loving family beagle may be the most photographed dog of all time. Since we got her as a 8-week old puppy, to now, just under three years later, we have accumulated over 6,000+ photos of the dog.
Excessive?
Perhaps. But I love dogs. A lot. Especially beagles. So it should come as no surprise that as a dog owner, I spend a lot of time playing tug-of-war with Jemma’s favorite toys, rolling around on the kitchen floor with her as we roughhouse, and yes, snapping tons of photos of her with my iPhone.
Over this past weekend I sat down and tried to organize the massive amount of photos in iPhoto. Not only was it a huge undertaking, I started to notice a pattern fairly quickly — there were lots of photos with excessive amounts of blurring.
Whether due to sub-par photography skills, trying to keep up with super-active Jemma as she ran around the room, or her spazzing out right as I was about to take the perfect shot, many photos contained a decent amount of blurring.
Now, for the average person I suppose they would have just deleted these blurry photos (or at least moved them to a separate folder) — but as a computer vision scientist, that wasn’t going to happen.
Instead, I opened up an editor and coded up a quick Python script to perform blur detection with OpenCV.
In the rest of this blog post, I’ll show you how to compute the amount of blur in an image using OpenCV, Python, and the Laplacian operator. By the end of this post, you’ll be able to apply the variance of the Laplacian method to your own photos to detect the amount of blurring.
Variance of the Laplacian

My first stop when figuring out how to detect the amount of blur in an image was to read through the excellent survey work, Analysis of focus measure operators for shape-from-focus [2013 Pertuz et al]. Inside their paper, Pertuz et al. reviews nearly 36 different methods to estimate the focus measure of an image.
If you have any background in signal processing, the first method to consider would be computing the Fast Fourier Transform of the image and then examining the distribution of low and high frequencies — if there are a low amount of high frequencies, then the image can be considered blurry. However, defining what is a low number of high frequencies and what is a high number of high frequencies can be quite problematic, often leading to sub-par results.
Instead, wouldn’t it be nice if we could just compute a single floating point value to represent how blurry a given image is?
Pertuz et al. reviews many methods to compute this “blurryness metric”, some of them simple and straightforward using just basic grayscale pixel intensity statistics, others more advanced and feature-based, evaluating the Local Binary Patterns of an image.
After a quick scan of the paper, I came to the implementation that I was looking for: variation of the Laplacian by Pech-Pacheco et al. in their 2000 ICPR paper, Diatom autofocusing in brightfield microscopy: a comparative study.
The method is simple. Straightforward. Has sound reasoning. And can be implemented in only a single line of code:
cv2.Laplacian(image, cv2.CV_64F).var()
You simply take a single channel of an image (presumably grayscale) and convolve it with the following 3 x 3 kernel:
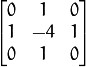
And then take the variance (i.e. standard deviation squared) of the response.
If the variance falls below a pre-defined threshold, then the image is considered blurry; otherwise, the image is not blurry.
The reason this method works is due to the definition of the Laplacian operator itself, which is used to measure the 2nd derivative of an image. The Laplacian highlights regions of an image containing rapid intensity changes, much like the Sobel and Scharr operators. And, just like these operators, the Laplacian is often used for edge detection. The assumption here is that if an image contains high variance then there is a wide spread of responses, both edge-like and non-edge like, representative of a normal, in-focus image. But if there is very low variance, then there is a tiny spread of responses, indicating there are very little edges in the image. As we know, the more an image is blurred, the less edges there are.
Obviously the trick here is setting the correct threshold which can be quite domain dependent. Too low of a threshold and you’ll incorrectly mark images as blurry when they are not. Too high of a threshold then images that are actually blurry will not be marked as blurry. This method tends to work best in environments where you can compute an acceptable focus measure range and then detect outliers.
Detecting the amount of blur in an image
So now that we’ve reviewed the the method we are going to use to compute a single metric to represent how “blurry” a given image is, let’s take a look at our dataset of the following 12 images:

As you can see, some images are blurry, some images are not. Our goal here is to correctly mark each image as blurry or non-blurry.
With that said, open up a new file, name it detect_blur.py , and let’s get coding:
# import the necessary packages
from imutils import paths
import argparse
import cv2
def variance_of_laplacian(image):
# compute the Laplacian of the image and then return the focus
# measure, which is simply the variance of the Laplacian
return cv2.Laplacian(image, cv2.CV_64F).var()
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--images", required=True,
help="path to input directory of images")
ap.add_argument("-t", "--threshold", type=float, default=100.0,
help="focus measures that fall below this value will be considered 'blurry'")
args = vars(ap.parse_args())
We start off by importing our necessary packages on Lines 2-4. If you don’t already have my imutils package on your machine, you’ll want to install it now:
$ pip install imutils
From there, we’ll define our variance_of_laplacian function on Line 6. This method will take only a single argument the image (presumed to be a single channel, such as a grayscale image) that we want to compute the focus measure for. From there, Line 9 simply convolves the image with the 3 x 3 Laplacian operator and returns the variance.
Lines 12-17 handle parsing our command line arguments. The first switch we’ll need is --images , the path to the directory containing our dataset of images we want to test for blurryness.
We’ll also define an optional argument --thresh , which is the threshold we’ll use for the blurry test. If the focus measure for a given image falls below this threshold, we’ll mark the image as blurry. It’s important to note that you’ll likely have to tune this value for your own dataset of images. A value of 100 seemed to work well for my dataset, but this value is quite subjective to the contents of the image(s), so you’ll need to play with this value yourself to obtain optimal results.
Believe it or not, the hard part is done! We just need to write a bit of code to load the image from disk, compute the variance of the Laplacian, and then mark the image as blurry or non-blurry:
# loop over the input images
for imagePath in paths.list_images(args["images"]):
# load the image, convert it to grayscale, and compute the
# focus measure of the image using the Variance of Laplacian
# method
image = cv2.imread(imagePath)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
fm = variance_of_laplacian(gray)
text = "Not Blurry"
# if the focus measure is less than the supplied threshold,
# then the image should be considered "blurry"
if fm < args["threshold"]:
text = "Blurry"
# show the image
cv2.putText(image, "{}: {:.2f}".format(text, fm), (10, 30),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 3)
cv2.imshow("Image", image)
key = cv2.waitKey(0)
We start looping over our directory of images on Line 20. For each of these images we’ll load it from disk, convert it to grayscale, and then apply blur detection using OpenCV (Lines 24-27).
In the case that the focus measure exceeds the threshold supplied a command line argument, we’ll mark the image as “blurry”.
Finally, Lines 35-38 write the text and computed focus measure to the image and display the result to our screen.
Applying blur detection with OpenCV
Now that we have detect_blur.py script coded up, let’s give it a shot. Open up a shell and issue the following command:
$ python detect_blur.py --images images

The focus measure of this image is 83.17, falling below our threshold of 100; thus, we correctly mark this image as blurry.

This image has a focus measure of 64.25, also causing us to mark it as “blurry”.

Figure 6 has a very high focus measure score at 1004.14 — orders of magnitude higher than the previous two figures. This image is clearly non-blurry and in-focus.

The only amount of blur in this image comes from Jemma wagging her tail.

The reported focus measure is lower than Figure 7, but we are still able to correctly classify the image as “non-blurry”.

However, we can clearly see the above image is blurred.

The large focus measure score indicates that the image is non-blurry.

However, this image contains dramatic amounts of blur.




What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this blog post we learned how to perform blur detection using OpenCV and Python.
We implemented the variance of Laplacian method to give us a single floating point value to represent the “blurryness” of an image. This method is fast, simple, and easy to apply — we simply convolve our input image with the Laplacian operator and compute the variance. If the variance falls below a predefined threshold, we mark the image as “blurry”.
It’s important to note that threshold is a critical parameter to tune correctly and you’ll often need to tune it on a per-dataset basis. Too small of a value, and you’ll accidentally mark images as blurry when they are not. With too large of a threshold, you’ll mark images as non-blurry when in fact they are.
Be sure to download the code using the form at the bottom of this post and give it a try!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Maybe you are going to expand this topic, but what would be really fascinating is if there is a way to take two very similar images and “repair” the blurred one with the unblurred one (I think this feature is in the new Photoshop).
Thanks for sharing this.
Great suggestion!
Check this publications.
http://www.ece.lehigh.edu/SPCRL/IF/multi_focus.htm
http://www.sciencedirect.com/science/article/pii/S0031320310000439
http://www.sciencedirect.com/science/article/pii/S0167865507000402
Thanks for passing them along! 😀
Thanks for great article .. can you suggest how we can deblur text in scanned documents?
great idea , that’s what i want to do with two images that i have with different modalities and different resolutions , i want to deblur the blurred one with the sharpened one
Adrian ,could you please give a method or suggestion with python code on this topic
thank you in advance
Since you have so many pictures, you could use deconvolution deblurring to fix the blur.
As usual, great post Adrian!!!
Thanks Chris! 🙂
Hey ! I just can’t get any output. No error nothing. I don’t understand why. Please help
I noticed all the pictures in your data set were either completely sharp or completely blurry. How did your program fare on pictures with a sharp background, but blurry subject? (i.e., the “Jemma spazzing out” ones)
They still did fairly well, but the results weren’t as good. To handle situations where only the subject of the image is blurry, I would suggest performing saliency detection (which I’ll do a blog post on soon) and then only computing the focus measure for the subject ROI of the image.
Great tutorial Adrian! any news on the saliency detection?
as reddit user 5225225 suggest, another trick would be to process the image” in blocks, and sorted it and compared based on the average of the top 10%. That way, if there’s some non-blurry parts and some blurry parts, you can effectively ignore the blurry parts.
That seems like it would work, because the actually blurry images look like every part of them is blurry, not just most of it as seen in the macro image.”
Source: https://www.reddit.com/comments/3k3fjr
Unfortunately, it’s not quite as easy to partition the image into blocks because you run the risk of the blurry region being partitioned between overlapping blocks. If you also take the top 10%, you could also run into false-positives. As for the saliency detection, I haven’t had a chance to investigate it more, I’ve been too busy with other obligations.
I think we have several different cases to cover:
Blur from motion of the subject. This is typically when your dog was moving.
The rest of the image can be sharp, but when the subject is moving – well…
Blur from moving the camera too much. Typically, nothing will be in sharp focus – unless you’re successfully performing motion tracking.
Blur from selective focus. This is something we strive to achieve from macro shots and the like.
Blur from “incorrect” focus. Nothing is sharp…
So – if everything is out of focus, I think we can safely declare the image “out of focus” and leave it up to the photographer if that is desirable or not.
But if we find some sharp and some out-of-focus elements then iit becomes difficult to tell them apart since we must somehow determine if the in-focus elements are the subject (selective focus) or the surroundings (motion blur due to the subject moving too much).
Hmh. Interesting problem!
Hi Adrian! Your blog posts are very helpful 🙂
Can you please share the link to the blog post which contains instructions on how to know whether the subject of the image is blurry (with a clear background)?
A quick question, if the distance of the subject from the camera keeps changing then will a constant focus measure threshold suffice. As per my observations, the threshold of focus and subject’s distance from the camera are relative.
Any leads on how to set a threshold and identify blur subject in a clear background will be of great help. Thanks in advance!
Sorry, I don’t have such a blog post.
A nice feature to add, would be to rename the original file name and append “-blurry” to it, so that users can go to the folder after and quickly filter the files.
This is a very helpful blog. Thanks!!!
I don’t use python, but I port the ones I need to Java/Android.
Very nice Nick!
Hey Nick,
Can you share the converted code from python to java/android??
Hi @Sarang, Did you get converted Android code?
@vigneshwaran: Any updates on your progress for the same ?
i follow your instruction and realize that Laplace filter is very sensitive with noise. So i wonder how do you choose threshold and what can we do in case of noisy image?
Indeed, the Laplacian can be sensitive to noise. You normally choose your threshold on a dataset-to-dataset basis by trial and error.
It may sound counterintuitive but you could apply a blur filter to each image before calculate the blur score. Since all images would have the same blur factor applied it should still be fair to compare their blur scores after. This could also be a way to segment into three categories: clear, blurry, noisy. based on the change in score before blurring and after blurring… or rate of change if you test at different levels of deliberate blurring. The rate of change of blur score may have a different slope depending on the amount of noise or other factors in the original image.
Oh my Jesus, i recently working on a project related to blur detection. and i have tried a edge width approach, finally i got stuck at finding the length of all edges. Now i have found this method and i wondering how to get a laplacian ‘s variance of image in java. Hope someone can help me indeed.
I haven’t coded Java in a long, long time, but computing the Laplacian by hand is actually pretty simple. It’s even easier if you have the OpenCV + Java bindings installed. Here is some more information on computing the Laplacian by hand.
What doesn’t mean .var()?
I got that this is “variance of the Laplacian” but how to calculate it without OpenCV? What is inside this function?
Thank you
The
cv2.Laplacianfunction, as the name suggests, computes the Laplacian of the input image. This function is built-in to OpenCV. Thevar()method is a NumPy function. It computes the statistical variance of a set of data, which in this case is the Laplacian — hence the name “Variance of the Laplacian”.If you want to implement the Laplacian by hand, I suggest reading up on convolutions and kernels.
Awesome post Adrian! Wondering if there is a way to fix the blur? What if there was a single image of a book taken with a cell phone that was blurry. Would there be a way to apply some method to make it slightly non-blurry?
There are methods to “deblur” images; however, the results are less than satisfactory at the moment. If you’ve ever used Photoshop before, you’ve likely played around with these filters. They don’t work all that great, and “deblurring” is still a very active area of research.
Great work! Is there a way to automatically check if an image is blurred or not without using some threshold? 🙂
There are certainly other methods that can be used for blur detection (such as investigating the coefficients in the Fourier domain), but in general, most methods require a threshold of some sort. I’ll try to do a followup blog post to this one that contains a more “easier to control” threshold.
You could add an option to allow the user to input the file names of reference images that the user knows are “in focus” and “out of focus”. The program can use these to set a threshold. Perhaps a “minimally acceptable” reference image makes more sense. Then the user needs to input just one image file name. Pick the worst image that you would still find acceptable to keep then the program sets the score of that image as the threshold.
Hi Adrian ,
Did you get a chance to write a blog with more “easier to control” threshold ? The threshold for variance of Laplacian does not work on all the mobile phone that I test on. An HDR camera with gives blurred images even when variance value is about 5000 while a normal camera of old mobile phones gives blurred image when variance is around 72 ! The image scene captured by both camera is same. How do we generalize the algorithm for different camera ? Becuse even the clear images from old camera is classified as blurry at times. Any leads ? How can the camera properties be utilized to decide on threshold ?
I haven’t written a second blog post on blur detection yet (very busy with deep learning tutorials at the moment). I will try to write a “parameter free” version of blur detection in the future.
I’m interested to are the version of parameter free
Brilliant! Could you help me to convert this code to C++? Thank you in advance 🙂
do you have the c++ code,i really need
Very helpful, thanks. Is it possible to find blur directions? Can we get two floating point values representing x-blur and y-blur?
Sure, absolutely. But for this, I wouldn’t use the Laplacian. I would compute the Sobel kernel in both the x and y directions. See this blog post for more information on the Sobel operator.
Well done Adrian!! Another good post really helpfull
Thanks Rish! 🙂
hello Adrian,I am a graduate student come from Wuhan university.I recently working on a project related to blur detection too,it is helpful to me.But I find the variance is also small when the image is pure color or close to pure color even the image is clearness.The reason is that pure color image variance of Laplacian is close too.So,how to deal with this problem?Really looking forward to your reply!thank you!
I addressed this question in an email, but I’ll respond here as well. This blur detection method (as well as other blur detection methods) tend to examine the gradient of the image. If there is no gradient in the image (meaning pure color with no “texture”), there the variance will clearly be low. There are non-gradient based methods for blur detection and they are detailed in this survey paper on blur detection — I would suggest giving that a read.
where is the source code of python? I can’t find in the pdf which i donwload
You can download the source code to this post using the “Downloads” section of this tutorial.
Hi,
We try to capture high resolution frames with PI3 and 5Mpix and 8Mpix camera.
As long as nothing moves the photo is fine.
Since we like to use it inside a PIR MW motion sensor there will be always a person or object moving in front of the camera.
We noticed that the moving person/object is always blur on the captured frame.
Is this normal? Can we capture frames with moving opbjects that are not blur?
What are the limitations?
Motion blur can be a bit of a problem, especially because when humans watch a video stream we tend to not “see” motion blur — we just see a fluid set of frames moving in front of us. However, if you were to hit “pause” in the middle of the stream, you would likely see motion blur. Ways to get around motion blur can involve using a very high FPS camera or using methods to detect the amount of blur and then choose a frame with minimal blur.
Hi Adrian,
Thanks for this great post. You have done some good work here in explaining the Variance of Laplacian method.
I have a use case where the input image is going to be somewhat black and white only. Is variance of laplacian method play good there as well?
What do you think of Sum Modified Laplacian method, in general?
By the vary definition of the variance statistic the variance is only useful if your input images can actually “vary”. However, in this particular example you might still be able to use the Variance of Laplacian. If your images are captured under controlled conditions you can simply define a threshold that determines what “is blurry” versus “what is not blurry”.
Yes but which approach you would suggest in this case? There are too many approaches suggest by Perutz et al
Without seeing your dataset it’s honestly hard to give concrete advice. Spot-check a few of the algorithms that you think will perform reasonably and go from there.
Yes, thanks. Will try to take this discussion over the email.
While writing this comment, I thought of an idea about de-blurring an image upto an extent. What do you think of unsharp-masking?
Hey Adrian,
thanks a lot for the tutorial, I found it really useful and seems to work well for the problem I am considering! However I have two questions:
– the variance function is applied to the pixel data in “vector format” instead “matrix format”? I ask this because I used R and after the convolution I still have pixel data in “matrix format” and applying var() function to such dataset of course brings to a covariance matrix, not just a number.
– isn’t the “variance approach” sensitive to the “number of objects” captured into the photo? I mean, a “good focus photo” with just one object on flat background (i.e. classical iphone headphones image) could have a variance not higher than a “not so good focus photo” with lots of objects? I the answer is yes, how would you deal with it?
Thanks in advance for the reply and kind regards,
Riccardo
The variance function is computed across the entire matrix. It should return a single floating point value, at least that is the NumPy implementation (I’m not sure about R).
The variance method is sensitive to a good number of things, but where you’ll really struggle is with objects with a flat background or no texture. The variance will naturally be very low in this case.
Great article!!
Can you or someone develop a Lightroom plugin based on this knowledge, in order to browse a cataloging mark all the photos with a Blurry or Non-Blurry tag?
I haven’t used Lightroom and I don’t know anything about their development ecosystem, but yes, I would assume that it’s possible.
Awesome article Adrian!
What do you think about solving this problem using convolutional neural network?
You can train a CNN to classify just about anything, so provided you have enough examples of blurry vs non-blurry images (in the order of tens of thousands of examples, ideally) then yes, a CNN could likely do well here.
Hi Adrian, thanks for the tutorial, it really helped me a lot.
I have one question, instead classify an image as blurred or not blurred, how can I isolate the non blurred area in the image? For example, in your figure 7, where the blur comes from Jemma’ tail, how can I extract this area from the photo?
Any advice would be great
Jose Soto
Hi Adrian, your tutorials are great .But i want to deblur the image .Please suggest any solution
I don’t have any tutorials on deblurring, but I will consider this for a future blog post.
Hi,
Thank you for such a well explained tutorial.
Have you got a chance to work out on/go through good methods for setting up an optimal threshold for blurr image classification ?
I really appreciate your blog posts. I’ve bought your book and supported the kick starter for the new one.
How would I got about implementing blur detection on a region of interest? (I assume I just slice the array) But what if that ROI is not a rectangle, but something made with a mask? For example, I want to focus on a face?
Is the best way to just find the ROI, then find the largest rectangle I can slice out of it?
How you find and determine your ROI is up to you and is highly dependent on what you are trying to accomplish. Edge detection, thresholding, contour extraction, object detection, etc. can all be used for determining what your ROI is. Once you have your ROI, you would need to compute the bounding box for it, extract the ROI via array slicing, and then compute the blur value.
Thanks!
This code failed on my dataset :’D The blurred one said not blurry and vice versa for some images.
You may need to tune the threshold of what is considered “blurry” versus “not blurry” for your own dataset.
Presumably this could be skewed by large in focus areas with little variation – for instance a large area of sky, or or carpet, would likely lead to a low value being returned even if the image was in focus.
Although this would only work if such areas were at the edge(s) of images, perhaps auto-cropping the image before analysis would help here, based on some threshold for colour variation?
great post would love to see this implemented in an over the shelf product or a google photos extension. I have a lot of photos that I have acquired over the years and I have adopted a new strategy this year to keep only the best, as opposed to keeping everything. an easy way to eliminate is to find blurred photos.
Hi Adrian, what a great post. I have an electronic focuser for my telescope that drives my telescope focus tube. I’ve added an Arduino in front of it powered by a python link and I’ve been using the standard deviation like this:
np.concatenate([cv2.meanStdDev(cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY))]).flatten()
to test my focus. Honestly it’s been quite hard, you’ve put a Laplacian in front of it, does that make any difference? Anyhow I’ll try your formula.
My real problem is that the number is very sensitive and changes for all sorts of reasons, a cloud moves in the sky, neighbour turns a light on, car goes past, none of which alter the focus but they do affect the contrast.
What do you think?
Regards
I would suggest breaking out your code a little more to make it more readable with less composite functions (that way you can reuse function outputs). The
cv2.meanStdDevwill return both the mean and standard deviation. You only need the variance for the Laplacian.As for applying this technique for examining skies, I’m not sure it’s the best approach. Provided a cloudless night, there will be very little texture and therefore the variance will be low. As you noted, if a cloud moves in, the variance increases from the baseline. I would suggest looking at other methods, including the distribution of Fourier transform coefficients.
Hi Adrian, thanks for your answer. I agree with you, I should break out the code some more. I think I might also just highlight the object I’m interested in and manage the focus in a sub-section of the image. It should be faster as well as being potentially more accurate.
Wonderful tutorial.
Please fix this:
pip intall imutils -> pip install imutils
Thank you for pointing out the typo, Marius!
Hi Adrian, It was a great post.
I am facing a problem for highly focused images while blur detection. The Laplacian result is returning a low value for highly focused images. Is there any method to identify the image is blurred or not especially for focused images?
Image – http://rhdwalls.com/wp-content/uploads/2016/08/Emma-Watson-15.jpg
If there there is little “texture” in the image, then the variance of the Laplacian will by definition be low. In that case, I would compute a histogram of the Fourier transform coefficients and inspect the slope. I will try to do a more advanced blog post on blur detection in the future.
Thanks for the update Adrian.
Hi Adrian, just wonder if you have had chance to do an advanced blog post. I’m having similar issue as Gayathri had. Highly focused images are detected as blurry images because of low variance.
I have not. I hope to one day cover it but cannot guarantee when that may be.
I am running this code on command prompt, but getting this message
usage: detect.py [-h] -i IMAGES [-t THRESHOLD]
detect.py: error: argument -i/–image is required
Please read up on command line arguments, how they work, and how to supply them to your Python script. This will resolve your error.
Thanks Adrian! Nice post. There are plenty of discussions on how to improve/detect blurriness. But, no one come up with full-pledged implementation. This is a wonderful blog you’re maintaining. Thanks again.
Thank you Mallesh, I appreciate it 🙂
Thanks a lot Adrian for the nice post. Just a small question. For the variance of Laplacian, After we convolve the image with the 3 x 3 kernel (Laplacian), the pixel values will apparently change. Do we apply the variance on “all” the pixels? In other words, would the variance be calculated for the “whole” image, and based on that result we can determine whether the image is blurry or not when compared against a threshold?
The variance is computed over the entire output of the Laplacian operation, not just the 3×3 region.
He is a good boy/girl (your dog I mean)… good job man!
Jemma is a girl and yes, she’s certainly good 🙂 Thanks for the comment.
Is it possible to use logistic regression to determine the threshold between blurred and not blurred in huge dataset? One could label a few image from the dataset into blurred and not blurred then calculated their corresponding laplacian variance. This is followed by logistic regression. The model can then be used to classify the rest of the images in the dataset.
Yes, you can use machine learning to help improve the blur detection but keep in mind that the model will only perform well if the input data matches what it was trained on. As I mentioned to “Prakruti” in the comment below I will try to do an updated blog post on “parameter free” blue detection in the future.
Thank you for the amazing tutorial and trying to answer all our follow-up questions!
Is there a similar and decently performing method to detect ‘glare/reflection/spots/’ in an image? Example image: http://i.ebayimg.com/images/i/370396881797-0-1/s-l1000.jpg
Glare and reflection are a nightmare to deal with but you might consider applying a Gaussian blur followed by binarization at the 75-80% level of a grayscale image (or maybe even the Value component of HSV). This will highlight regions of an image that are very bright. It’s not perfect, but it would be a start.
It would be great if you provided a stand-alone executable (or installable) app to do the task. We not-programmers also need these tools, and there is none out there.
Hi Majid — while it’s not impossible to create a Python + OpenCV stand-alone executable that can be executed across all machines, it’s very close to it. I can certainly understand non-programmers wanting to use these tools and lessons, but please do keep in mind that PyImageSearch is a programming-based blog (in the Python programming language) and programming experience is more-or-less required to read this blog. Furthermore, a standalone executable with Python is again, near impossible when using OpenCV.
I’m wondering if this method can be adapted by Google Images to help them determine which images have been upsampled (and by how much). Do you know of any work being done in that area? I see nothing on the web but it seems important for anyone doing serious image searches.
Hi Tom — my upcoming blog post on Monday, November 27th 2017 (image hashing) will address part of this question (i.e., determining the same images).
Hi Adrian, I’ve just discovered just site and it looks very interesting. I was wondering, with this method, how do you account for photos with bokeh (i.e., photos with the background intentionally blurred, like for portraits).
The algorithm cannot tell the difference between unintentional and intentional blur. I’m not sure what your question is in this context. Is your goal to see if the subject is blurred but ignore the rest of the blur in the background?
Whenever I go out on vacation, I love to take pictures. I recently got a mirrorless camera so I could dive a little deeper into photography. However, I usually take a lot of pictures (more than 1000 last vacation) and I thought of quickly discarding some of them using code (for example, those which are too blurry). I know the algorithm cannot tell the difference between intentional and unintentional blur. I was just wondering if this algorithm could be used, and choose a different threshold, so that blurry images could be discarded (or marked as blurry), but images with intentional blurr could still be marked as “not blurry” (not because of the algorithm, but maybe by choosing a different threshold), Or would I need a different approach?
If there was such a threshold you would need to manually tune it and determine it yourself. Or perhaps you would need to leverage a machine learning classifier to learn what blurry, not blurry, and intentional blurry looks like.
Hi Adrain
If I want to compare the blurriness of images acquired in different environments, do I need to normalize the intensity of these image into same scale?
This method is only meant to detect blurriness, not compare blurriness. You might want to instead treat this as an image search engine/CBIR problem by computing features from the FFT or even wavelet transformation of the image.
I got it! Thanks for your suggestion. I will try the method you mentioned.
Does anyone know why the images do not get parsed in order by filename? I’m running this on a folder with about 2000 files in it. The images are being called up in seemingly random order.
There is no order imposed on the image paths. You would need to explicitly sort them:
for imagePath in sorted(paths.list_images(args["images"])):Perfect. Thanks!
Hi, i have problems in line 16
ap.add_argument(“-i”, “–images”, required=True,
after i run this line, it show error
ap.add_argument(“-i”, “C:\\Users\\Bunkbed\\Downloads\\Compressed\\detecting-blur\\detecting-blur\\images\\image_001.png”, required=True,
File “”, line 1
ap.add_argument(“-i”, “C:\\Users\\Bunkbed\\Downloads\\Compressed\\detecting-blur\\detecting-blur\\images\\image_001.png”, required=True,
^
SyntaxError: unexpected EOF while parsing
Please help me
You do not need to edit the code. See this blog post on command line arguments.
Hi,
I have implemented the link tutorial above to detect blur images. I want to ask, what value is raised in the picture what value? is it the blur level? and if I insert images of different sizes, the larger the size of the image, the value that comes out is also very large.
Oh yes, here’s my screenshot of my experiment, I’m having trouble because the displayed image does not adjust its size, the picture is enlarged and can not zoom out. Do you have a tutorial or suggestion how to resize the output of the image so that it appears the whole picture?
One more thing, I want to make the blur value resulting from the blur detection as a parameter, is there a way or tutorial to normalize the blur value into the range of 1 -100? and also how to label the blur values to categories like good images, good kurng (can be enhancement) and can not be fixed.
Typically we do not process images larger than 400-600px along their maximum dimensions. You should be resizing your input images to this approximate size before trying to compute the blur detection. The value that is being computed is the “variance of the Laplacian”. I discuss it in the post. As for your screenshot perhaps you forgot to include it?
Hi, Adrian.
I want to create a blur detection on Identity Card, which is different to your sample images.
Is there any “universal threshold” for detecting blur images?
Using this method, unfortunately no, there is no such thing as a “universal threshold”. If you’re building an identity card recognition system I would suggest gathering images of the cards, both blurry and not, and seeing if you can find a reasonable threshold.
Ouch, I’m sorry for my question.
I mean, the case is just take a photo of identity card and determine it is blur or not.
Is there any such thing like “universal threshold” for it?
See my previous comment: no, there is no such thing as “universal threshold”.
Hi Adrian,
I have tried the algorithm with different images context then compare it to your sample images (ex : card, car, etc). After some experiments, I should set different threshold. Why can it happen? Are there any factors affect the threshold?
Hi Rendy — the “focus measure” Line 26 is affected by the blurriness of the image. Your supplied command line argument
--thresholdis compared to this value. The only factor that affects the threshold is you changing it at runtime. See the command line arguments blog post as needed.I mean, what are the scientific or quantitative reason that affect threshold arrangement?
Sorry, I think I should repair my question.
why the threshold between your sample images and my sample images (ex: card) is different? is there any quantitative reason?
The threshold is normally set manually. You try various thresholds experimentally and manually until you find one that works well for your dataset.
Hi adrian, i want to blur detection for card image, then this card has color light blue and dark blue, I want to ask how the effect light blue and dark blue in blur image? thank you
Hey Robert, I’m not sure what you mean by how the light blue vs. dark blue would effect the blurring. Could you elaborate?
Hi Adrian, would you have any tutorial in hand for performing deblurring in a real time video application? Or maybe any other tricks envolving deblurring with opencv? I really appreciate your help.
Sorry, I do not have any tutorials or content related to deblurring. I will certainly consider it for a future topic, thank you for the suggestion!
HI Adrian,I admired your works!
While processing, I faced some problems.When I feed the bigger-sized image to detect the blur, the model only caputured part of image,and also only detect blur on the part of it. Do you have any suggestion?
Hey Andy — I’m not sure I’m fully understanding your question. Are you asking how to detect blur in only a single part of an image?
Hey Adrian, I mean when I feed a image that size is 1280*720,the model functioned correctly.
original image: https://imgur.com/aEDNWJW
result: https://imgur.com/oJdTaBo
While I feed a image that size is 5152*3864,the model captured only part of image and detected blur on it.
original image: https://imgur.com/290Ct2e
result: https://imgur.com/aZCJ2D2
(It seems like the image was captured upper left)
Hey Andy — I’m not sure why that would be, that doesn’t make much sense. I think your script may have skipped over an image or something. Secondly, I’ll add that we rarely process images that are greater than 1000px across the largest dimension. I would suggest you resize your images as it will (1) speedup your pipeline and (2) provide more accurate results.
HI Adrian ,I have a similar but slightly different question. What I want is an algorithm that cuts or detects the out of focus(or blurred) areas and want to remove the blurry area When the clear area overlaps with the hazy area.
That’s a bit more complicated. You could try using a sliding window to loop over ROIs, compute the blur score, and then remove if necessary. It’s a bit of a hack but could work for your application.
Hi. I have a variety of images with different resolution(height and width of image). so, is the focus or threshold value which you chose also dependent on resolution or height and width of the image? what i mean is can a image of high resolution say 2160*1280, be blurry and similarly an image of 640*480 have high focus value.
And if it does depend on resolution, do we need to set different threshold values for different image resolutions.
Yes, you would need to set different thresholds for each of the resolutions/image types.
Hi Adrian
Thanks a lot. I used your algorithm to detect condensation in glass door refrigerator along raspberry pi and pi camera. Honestly this algorithm rocks, it achieved 99% successful detection rate.
Awesome! Congrats on a successful project, Alan! 😀
Hi Adrian ,
I have used this above algorithm (Laplacian method) for blur detection on a data-set with around 4000 images containing blur and non-blur images.
The blur is due to human motion. But the results are not consistent for me. Can you please help me in sorting this problem.
How to solve this error?
usage: detect_blur.py [-h] -i IMAGES [-t THRESHOLD]
detect_blur.py: error: the following arguments are required: -i/–images
You need to supply the command line arguments to the script. If you are new to command line arguments refer to this tutorial.
This site is amazing, i found very good stuff here, thanks for for the help!
Thanks Deividson, I really appreciate that 🙂
Hi Adrian, I have the same problem of Shubham:
detect_blur.py: error: the following arguments are required: -i/–images
I saw u refer to this tutorial but i am not the best with python, can u specificy and help me?
sorry for english, i am from colombia, best regards!
Follow this tutorial on command line arguments. It’s okay if you are new to Python but you need to take the time to invest in your general programming skills.
Hi Adrian,
Thank you for the great article. I’ve a question. Say I have 2 pics, I want to detect blur level of pic_1, and take a sharp image, pic_2, and blur it to the same extent as pic_1. Can you please advise me on how to achieve this.
Thanks in advance.
Maybe you can keep applying a guassian filter to the image and compare both images. If the difference starts to get larger means that your previous amount of blurring was closest to the second image.
Is possible detect if the photo contain micro motion blur, is not blurry but contain some motion blur.
Because the camera was shaked
Hi Adrian,
Thanks a lot for the great post,
I want to measure the amount of the blurred image (ANPR system), then apply the deblur(wiener) filter to improve the image, How do apply the amount of deblurred to deblurred algorithms?
Sorry, I don’t have any tutorials on deblurring. Good luck with it!
Hi Adrian, how about faded images, what metrics would you look at? I have a large dataset of passport-style photos that are scanned, but a number of them are faded (i.e getting old with time). So, I tried a number of image quality metrics, but they don’t work so well since the scan itself isn’t “bad quality”, it’s the subject of the scan (the passport photo) that’s the issue. What do you suggest I try and do?
You solution works perfectly!!! Thank you!! Without Ph.D like you many problems may remains unsolved!!
Thank you again!
Congrats Mattia, I’m glad the code helped you 🙂
Hi Adrian,
Thanks for this insightful post. I actually wanted to know if blurriness and pixelation is the same thing.
If not, how do you detect pixelation?
No, they are not the same thing. Pixelation is often caused by a low resolution or low quality images. Blurriness can be caused by a poor camera sensor, motion, or post-processing.
Hi Adrian, your blog is awesome. Thank you so much.
Thanks so much 🙂
Hi Adrian, great stuff! One question: Why do you use cv2.CV_64F as depth?
We need a floating point data type for negative values. An unsigned 8-bit integer cannot handle negative values.
Hey, This was very helpful. I was wondering how do we separate the blurry and not blurry images into different folders?
You can use Python’s “shutil” library to copy files.