
Today’s blog post is part one in a two part series on installing and using the Tesseract library for Optical Character Recognition (OCR).
OCR is the automatic process of converting typed, handwritten, or printed text to machine-encoded text that we can access and manipulate via a string variable.
Part one of this series will focus on installing and configuring Tesseract on your machine, followed by utilizing the tesseract command to apply OCR to input images.
In next week’s blog post we’ll discover how to use the Python “bindings” to the Tesseract library to call Tesseract directly from your Python script.
To learn more about Tesseract and how it can be used for OCR, just keep reading.
Installing Tesseract for OCR
Tesseract, originally developed by Hewlett Packard in the 1980s, was open-sourced in 2005. Later, in 2006, Google adopted the project and has been a sponsor ever since.
The Tesseract software works with many natural languages from English (initially) to Punjabi to Yiddish. Since the updates in 2015, it now supports over 100 written languages and has code in place so that it can easily be trained on other languages as well.
Originally a C program, it was ported to C++ in 1998. The software is headless and can be executed via the command line. It does not come with a GUI but there are several other software packages that wrap around Tesseract to provide a GUI interface.
To read more about Tesseract visit the project page and read the Wikipedia article.
In this blog post we will:
- Install Tesseract on our systems.
- Validate that the Tesseract install is working correctly.
- Try Tesseract OCR on some sample input images.
After going through this tutorial you will have the knowledge to run Tesseract on your own images.
Step #1: Install Tesseract
In order to use the Tesseract library, we first need to install it on our system.
For macOS users, we’ll be using Homebrew to install Tesseract:
$ brew install tesseract
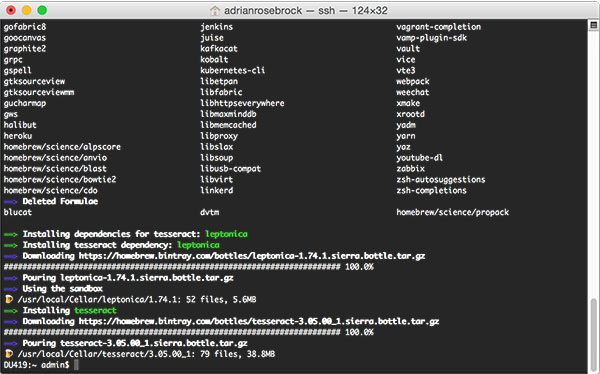
If you’re using the Ubuntu operating system, simply use apt-get to install Tesseract OCR:
$ sudo apt-get install tesseract-ocr
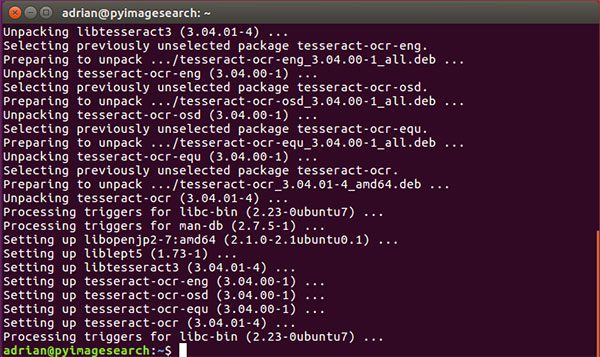
For Windows, please consult Tesseract documentation as PyImageSearch does not support or recommend Windows for computer vision development.
Step #2: Validate that Tesseract has been installed
To validate that Tesseract has been successfully installed on your machine, execute the following command:
$ tesseract -v tesseract 3.05.00 leptonica-1.74.1 libjpeg 8d : libpng 1.6.29 : libtiff 4.0.7 : zlib 1.2.8
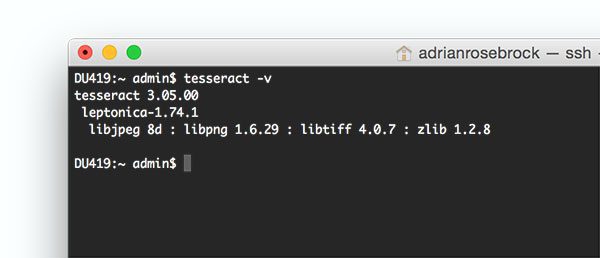
You should see the Tesseract version printed to your screen, along with a list of image file format libraries Tesseract is compatible with.
If you instead get the error:
-bash: tesseract: command not found
Then Tesseract was not properly installed on your system. Go back to Step #1 and check for errors. Additionally, you may need to update your PATH variable (for advanced users only).
Step #3: Test out Tesseract OCR
For Tesseract OCR to obtain reasonable results, you’ll want to supply images that are cleanly pre-processed.
When utilizing Tesseract, I recommend:
- Using as an input image with as high resolution and DPI as possible.
- Applying thresholding to segment the text from the background.
- Ensuring the foreground is as clearly segmented from the background as possible (i.e., no pixelations or character deformations).
- Applying text skew correction to the input image to ensure the text is properly aligned.
Deviations from these recommendations can lead to incorrect OCR results as we’ll find out later in this tutorial.
Now, let’s apply OCR to the following image:

Simply enter the following command in your terminal:
$ tesseract tesseract_inputs/example_01.png stdout Warning in pixReadMemPng: work-around: writing to a temp file Testing Tesseract OCR
Correct! Tesseract correctly identified, “Testing Tesseract OCR”, and printed it in the terminal.
Next, let’s try this image:

Enter the following in your terminal, noting the changed input filename:
$ tesseract tesseract_inputs/example_02.png stdout Warning in pixReadMemPng: work-around: writing to a temp file PyImageSearch
Success! Tesseract correctly identified the text, “PyImageSearch”, in the image.
Now, let’s try OCR’ing digits as opposed to alphabetic characters:
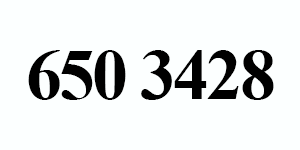
This example uses the command line digits switch to only report digits:
$ tesseract tesseract_inputs/example_03.png stdout digits Warning in pixReadMemPng: work-around: writing to a temp file 650 3428
Once again, Tesseract correctly identified our string of characters (in this case digits only).
In each of these three situations Tesseract was able to correctly OCR all of our images — and you may even be thinking that Tesseract is the right tool for all OCR uses cases.
However, as we’ll find out in the next section, Tesseract has a number of limitations.
Limitations of Tesseract for OCR
A few weeks ago I was working on a project to recognize the 16-digit numbers on credit cards.
I was easily able to write Python code to localize each of the four groups of 4-digits.
Here is an example 4-digit region of interest:

However, when I tried to apply Tesseract to the following image, the results were dissatisfying:
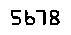
$ tesseract tesseract_inputs/example_04.png stdout digits Warning in pixReadMemPng: work-around: writing to a temp file 5513
Notice how Tesseract reported 5513 , but the image clearly shows 5678 .
Unfortunately, this is a great example of a limitation of Tesseract. While we have segmented the foreground text from background, the pixelated nature of the text “confuses” Tesseract. It’s also likely that Tesseract was not trained on a credit card-like font.
Tesseract is best suited when building document processing pipelines where images are scanned in, pre-processed, and then Optical Character Recognition needs to be applied.
We should note that Tesseract is not an off-the-shelf solution to OCR that will work in all (or even most) image processing and computer vision applications.
In order to accomplish that, you’ll need to apply feature extraction techniques, machine learning, and deep learning.
What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
Today we learned how to install and configure Tesseract on our machines, the first part in a two part series on using Tesseract for OCR. We then used the tesseract binary to apply OCR to input images.
However, we found out that unless our images are cleanly segmented Tesseract will give poor results. In the case of “noisy” input images, we’ll likely obtain better accuracy by training a custom machine learning model to recognize characters in our specific use case.
Tesseract is best suited for situations with high resolution inputs where the foreground text is cleanly segmented from the background.
Next week we’ll learn how to access Tesseract via Python code, so stay tuned.
To be notified when the next blog post on Tesseract goes live, be sure to enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Thank you for your professionalism and always interesting newsletter.
Thank you Mans, I’m happy to hear you are enjoying the PyImageSearch blog 🙂
Thank you Dr. Rosebrock, I always follow your articles. I will try to understand how tesseract works now.
How to install version 4.xx on raspberry-pi
executing the same command showing my tesseract is latest version but i want to use 4.xx .
can you help me
sorry about my English and Thanks in Advance
I found that my raspberry pi is based on ARM64 architecture which doestn’t support version 4.xx
I will be creating a dedicated tutorial for Tesseract 4. Stay tuned! 🙂
Hi Jibin, be sure to refer to Adrian’s new post on Tesseract 4 — Raspberry Pi instructions are included.
Hello sir, how can we add custom database fonts in tesseract, i followed some on-line sites but no results. Can you please help out on this for my academic project.
Take a look at “Daniel Paull”‘s comment.
Thanks for this. While there are free online services for OCR, they are web / gui based and not helpful. The Google Drive OCR option for uploaded documents is also web /gui based. The Google cloud platform OCR does a good job, but it still requires uploading the image to the cloud, subsequently using an API to do the OCR. But Google OCR API is not free and a bit of a pain to use. Tesseract can run locally without uploading anything to the internet. This command line approach worked well for me and I look forward to Part 2 so I can use it from Python.
I am yet to study denoising of images. Nevertheless my question is about denoising a noisy image in order to apply the tesseract package to a denoised image.
Do you have tutorials in your blog about denoising. So that one can apply denoising techniques on a noisy image then perform OCR using the tesseract?
Anthony from Sydney NSW
Hi Anthony — next week’s blog post will be an example of how to cleanup images before passing them through Tesseract to increase OCR accuracy.
Does this mean that a machine neural network would actually be better than using Tesseract in the average case? I’ve tossed credit cards at these at this point and they seem to perform pretty good.
It really depends on your application and how cleanly segmented your images are. If your images are nice and segmented, Tesseract can do very, very well. If you have a lot of noise and variation in your characters, it might be worth considering training your own neural network.
Hi
Is it possible use for another language?,how?
Thank you .
Take a look at the “Other Languages” section of the official Tesseract documentation.
G’day Adrian,
I’ve recently spent a lot of time getting Tesseract to work nicely for OCR of some documents. I found that disabling the use of dictionaries (since I’m not not parsing prose), using character whitelists and training for specific fonts was needed to get reliable results. As an aside, if you need to train for a specific font, give this website a crack (I have no affiliation with them, but found it useful):
http://trainyourtesseract.com/
Noise is a problem for sure. I use morphological operators to fill and smooth, but I still get some problems. Doing your own thresholding is a must as the built in thresholding seems pretty basic and doesn’t do a very good job.
Once you get it working for a given application, Tesseract can work well. But, it certainly needs a lot of hand holding to get there.
Thank you for sharing, Daniel! I had never used TrainYourTesseract before, I will certainly give it a look.
Thanks for another great article!
I haven’t used Tesseract before, but thanks to this article I should be able to 🙂
Just one thought about the statement “PyImageSearch does not support or recommend Windows for computer vision development”,
About a year back I would have agreed with you (and I use Linux for most of my development still). But Windows has matured a lot since then, and many computer vision and machine learning tools/libraries does work quite well with Windows now. I think it’s worth a shot giving Windows a chance.
(Here’s some posts I made on setting up things on Windows: http://www.codesofinterest.com/search/label/Installation)
Just a thought 🙂
I agree with Windows has matured a lot, especially with the bash inclusion, but I still don’t recommend it for computer vision development. Microsoft is doing some really neat things with their APIs, but Windows itself isn’t conducive to computer vision development. Furthermore, as the writer of PyImageSearch I can only support what I know, which is Unix. The support burden of having to troubleshoot Windows is simply far too high.
Hi Adrian,
I just recently subscribed to your messages and I have been playing with examples you created. I’m actually pretty new to Python and so far I’m enjoying the ride.
I have a question i’m hoping you can help me with. I have been testing out the results of running pytesseract with various options. Setting the config to “config=’-psm xx'” works just fine but I can’t get it to read my custom config file which I placed in my tessdata folder (C:\Program Files (x86)\Tesseract-OCR\tessdata\configs). Is there a different folder perhaps which stores the pytesseract config files?
Please help!
Edit : Just wanted to add that using the -c option in the config such as “-c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyz” also doesn’t seem to work. I still see values returned which are not in that list!
Actually…Never mind. Found what I needed. I can’t cancel this comment so…please help me do so.
Well done with the tutorials though!
Congrats on resolving the issue Dami!
Adrian,
Loved this introduction to Tesseract. Looking forward to learning about how to use Tesseract with Python next week. Thanks for providing great content!
Thanks Petes! 🙂
How to recognize Chinese?
I don’t know if Tesseract recognizes Chinese characters out of the box, but you should consult the documentation regarding the provided languages and how to train your own language classifier if need be.
Hi Adrian,
Thanks for the nice tutorial. Would it possible to read OCR using webcam video streaming?
Absolutely. You would need to localize the text in each frame first, then pass the text through Tesseract.
Thanks Adrian. Your directions are so clean and helpful. One question: before you start writing “$ tesseract tesseract_inputs/example_01.png stdout”
where does your PWD need to be?
i’m having issues and i think it’s path related. I have tesseract installed but i can’t manipulate it via python. i’ve gone through stack overflow and there isn’t help when installing tesseract via unix on a mac for python3.
many thanks,
justin
Your working directory shouldn’t matter here. Provided you have installed tesseract properly you should be able to execute the script from any location on your machine.
If you want to use Tesseract and Python together, please see this post.
A long time ago, I installed tesseract 3.05.01 for OCR using HomeBrew:
brew install –with-training-tools tesseract
How do I update it to the latest? I thought by regularly running the following, this would be done:
brew update
brew upgrade
brew outdated
However, my tesseract has not been updated at all…
Hello
I’m trying to intall tesseract 3.05, but when I do sudo apt-get install tesseract-ocr
I get tesseract 3.04.01. I also have noticed that your Figure 2 doesn’t match with your output from tesseract -v command: the first shows tesseract 3.04.01 installed, while the second says 3.05.00.
How can I install 3.05.00? I’m using linux by the way
Thanks in advance!
I gathered these results on both macOS and Linux to verify that they worked. If you need a specific version of Tesseract you should compile and install from source.
Hi Adrian!
Nice work and Great blog
I installed tesseract on Raspbian. However, the version is 3.04.01
I tried to upgrade it but I could not, what’s the problem?
From what I read, version 3.05 is provided with many more features and much improved version. Is this right?
I’m not sure what you mean by being unable to upgrade. Did you get an error message of some kind?
Hi! Adrian Rosebrock
Please help me, what is the location to install Pytessract OCR. I installed where all package is installed via pip, But still getting an error that Pytessract is not installed or path is not found?
Sorry for my English.
Thank you.
I am using Windows 10 OS.
Hey Ramjan, I don’t have a Windows machine and I don’t officially support Windows here on the PyImageSearch blog. Would you be able to try on Unix-based OS like macOS or Linux? Additionally, if you have any questions related to installing pytesseract on Windows I would definitely suggest posting on their official GitHub page. I know that doesn’t solve your exact question but I hope it at least points you in the right direction!
Hi,
I am using Oracle Linux. I couldn’t find complete steps to install in Linux machine.I installed in Ubuntu, for few for scanned PDFs its extracting unknown characters sometimes not.Can you please let me know the link how to install on Linux machine instead of Ubuntu.
Thanks & Regards,
Karim
Hey Karim — I use Ubuntu daily which is the Linux OS I have the most experience with. Unfortunately I do not have any tutorials dedicated to Oracle Linux.
How to use and install the Training Tools? In the Documentation it says i have to make the Training Tools from the Source Directory, but i already installed tesseract by “apt-get”.
(https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00)
Once the above additional libraries have been installed, run the following from the Tesseract source directory:
make
make training
sudo make training-install
Hi Rob — I’ve never personally trained a custom Tesseract model so I’m not sure how to use their training tools.
Hi Adrian, let me ask you a question. Why don’t you recommend use Windows for computer vision? Thanks, I love your posts and content. You are awesome 🙂
Refer to my FAQ. The short answer is while you can use Windows for computer vision and deep learning, I don’t recommend it. Unix systems such as Linux and macOS are much better suited for CV and DL.