
Today’s blog post on multi-label classification with Keras was inspired from an email I received last week from PyImageSearch reader, Switaj.
Switaj writes:
Hi Adrian, thanks for the PyImageSearch blog and sharing your knowledge each week.
I’m building an image fashion search engine and need help.
Using my app a user will upload a photo of clothing they like (ex. shirt, dress, pants, shoes) and my system will return similar items and include links for them to purchase the clothes online.
The problem is that I need to train a classifier to categorize the items into various classes:
- Clothing type: Shirts, dresses, pants, shoes, etc.
- Color: Red, blue, green, black, etc.
- Texture/appearance: Cotton, wool, silk, tweed, etc.
I’ve trained three separate CNNs for each of the three categories and they work really well.
Is there a way to combine the three CNNs into a single network? Or at least train a single network to complete all three classification tasks?
I don’t want to have to apply them individually in a cascade of if/else code that uses a different network depending on the output of a previous classification.
Thanks for your help.
Switaj poses an excellent question:
Is it possible for a Keras deep neural network to return multiple predictions?
And if so, how is it done?
To learn how to perform multi-label classification with Keras, just keep reading.
Multi-label classification with Keras
2020-06-12 Update: This blog post is now TensorFlow 2+ compatible!
Today’s blog post on multi-label classification is broken into four parts.
In the first part, I’ll discuss our multi-label classification dataset (and how you can build your own quickly).
From there we’ll briefly discuss SmallerVGGNet , the Keras neural network architecture we’ll be implementing and using for multi-label classification.
We’ll then take our implementation of SmallerVGGNet and train it using our multi-label classification dataset.
Finally, we’ll wrap up today’s blog post by testing our network on example images and discuss when multi-label classification is appropriate, including a few caveats you need to look out for.
Our multi-label classification dataset

The dataset we’ll be using in today’s Keras multi-label classification tutorial is meant to mimic Switaj’s question at the top of this post (although slightly simplified for the sake of the blog post).
Our dataset consists of 2,167 images across six categories, including:
- Black jeans (344 images)
- Blue dress (386 images)
- Blue jeans (356 images)
- Blue shirt (369 images)
- Red dress (380 images)
- Red shirt (332 images)
The goal of our Convolutional Neural network will be to predict both color and clothing type.
I created this dataset by following my previous tutorial on How to (quickly) build a deep learning image dataset.
The entire process of downloading the images and manually removing irrelevant images for each of the six classes took approximately 30 minutes.
When trying to build your own deep learning image datasets, make sure you follow the tutorial linked above — it will give you a huge jumpstart on building your own datasets.
Configuring your development environment
To configure your system for this tutorial, I recommend following either of these tutorials:
Either tutorial will help you configure you system with all the necessary software for this blog post in a convenient Python virtual environment.
Please note that PyImageSearch does not recommend or support Windows for CV/DL projects.
Multi-label classification project structure
Go ahead and visit the “Downloads” section of this blog post to grab the code + files. Once you’ve extracted the zip file, you’ll be presented with the following directory structure:
├── classify.py ├── dataset │ ├── black_jeans [344 entries │ ├── blue_dress [386 entries] │ ├── blue_jeans [356 entries] │ ├── blue_shirt [369 entries] │ ├── red_dress [380 entries] │ └── red_shirt [332 entries] ├── examples │ ├── example_01.jpg │ ├── example_02.jpg │ ├── example_03.jpg │ ├── example_04.jpg │ ├── example_05.jpg │ ├── example_06.jpg │ └── example_07.jpg ├── fashion.model ├── mlb.pickle ├── plot.png ├── pyimagesearch │ ├── __init__.py │ └── smallervggnet.py ├── search_bing_api.py └── train.py
In the root of the zip, you’re presented with 6 files and 3 directories.
The important files we’re working with (in approximate order of appearance in this article) include:
search_bing_api.py: This script enables us to quickly build our deep learning image dataset. You do not need to run this script as the dataset of images has been included in the zip archive. I’m simply including this script as a matter of completeness.train.py: Once we’ve acquired the data, we’ll use thetrain.pyscript to train our classifier.fashion.model: Ourtrain.pyscript will serialize our Keras model to disk. We will use this model later in theclassify.pyscript.mlb.pickle: A scikit-learnMultiLabelBinarizerpickle file created bytrain.py— this file holds our class names in a convenient serialized data structure.plot.png: The training script will generate aplot.pngimage file. If you’re training on your own dataset, you’ll want to check this file for accuracy/loss and overfitting.classify.py: In order to test our classifier, I’ve writtenclassify.py. You should always test your classifier locally before deploying the model elsewhere (such as to an iPhone deep learning app or to a Raspberry Pi deep learning project).
The three directories in today’s project are:
dataset: This directory holds our dataset of images. Each class class has its own respective subdirectory. We do this to (1) keep our dataset organized and (2) make it easy to extract the class label name from a given image path.pyimagesearch: This is our module containing our Keras neural network. Because this is a module, it contains a properly formatted__init__.py. The other file,smallervggnet.pycontains the code to assemble the neural network itself.examples: Seven example images are present in this directory. We’ll useclassify.pyto perform multi-label classification with Keras on each of the example images.
If this seems a lot, don’t worry! We’ll be reviewing the files in the approximate order in which I’ve presented them.
Our Keras network architecture for multi-label classification
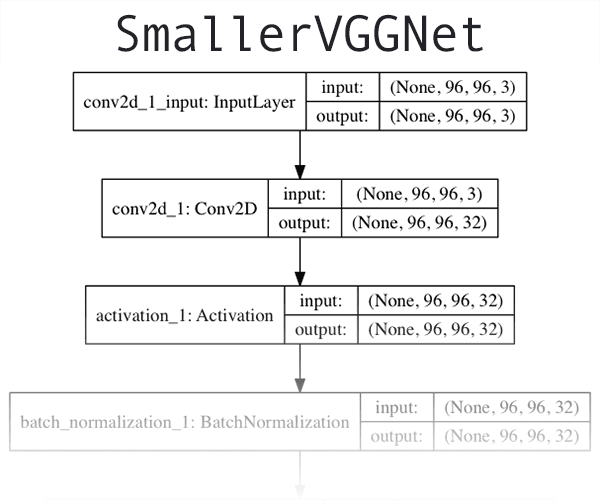
The CNN architecture we are using for this tutorial is SmallerVGGNet , a simplified version of it’s big brother, VGGNet . The VGGNet model was first introduced by Simonyan and Zisserman in their 2014 paper, Very Deep Convolutional Networks for Large Scale Image Recognition.
As a matter of completeness we are going to implement SmallerVGGNet in this guide; however, I’m going to defer any lengthy explanation of the architecture/code to my previous post — please refer to it if you have any questions on the architecture or are simply looking for more detail. If you’re looking to design your own models, you’ll want to pick up a copy of my book, Deep Learning for Computer Vision with Python.
Ensure you’ve used the “Downloads” section at the bottom of this blog post to grab the source code + example images. From there, open up the smallervggnet.py file in the pyimagesearch module to follow along:
# import the necessary packages from tensorflow.keras.models import Sequential from tensorflow.keras.layers import BatchNormalization from tensorflow.keras.layers import Conv2D from tensorflow.keras.layers import MaxPooling2D from tensorflow.keras.layers import Activation from tensorflow.keras.layers import Flatten from tensorflow.keras.layers import Dropout from tensorflow.keras.layers import Dense from tensorflow.keras import backend as K
On Lines 2-10, we import the relevant Keras modules and from there, we create our SmallerVGGNet class:
class SmallerVGGNet: @staticmethod def build(width, height, depth, classes, finalAct="softmax"): # initialize the model along with the input shape to be # "channels last" and the channels dimension itself model = Sequential() inputShape = (height, width, depth) chanDim = -1 # if we are using "channels first", update the input shape # and channels dimension if K.image_data_format() == "channels_first": inputShape = (depth, height, width) chanDim = 1
Our class is defined on Line 12. We then define the build function on Line 14, responsible for assembling the convolutional neural network.
The build method requires four parameters — width , height , depth , and classes . The depth specifies the number of channels in an input image, and classes is the number (integer) of categories/classes (not the class labels themselves). We’ll use these parameters in our training script to instantiate the model with a 96 x 96 x 3 input volume.
The optional argument, finalAct (with a default value of "softmax" ) will be utilized at the end of the network architecture. Changing this value from softmax to sigmoid will enable us to perform multi-label classification with Keras.
Keep in mind that this behavior is different than our original implementation of SmallerVGGNet in our previous post — we are adding it here so we can control whether we are performing simple classification or multi-class classification.
From there, we enter the body of build , initializing the model (Line 17) and defaulting to "channels_last" architecture on Lines 18 and 19 (with a convenient switch for backends that support "channels_first" architecture on Lines 23-25).
Let’s build the first CONV => RELU => POOL block:
# CONV => RELU => POOL
model.add(Conv2D(32, (3, 3), padding="same",
input_shape=inputShape))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(3, 3)))
model.add(Dropout(0.25))
Our CONV layer has 32 filters with a 3 x 3 kernel and RELU activation (Rectified Linear Unit). We apply batch normalization, max pooling, and 25% dropout.
Dropout is the process of randomly disconnecting nodes from the current layer to the next layer. This process of random disconnects naturally helps the network to reduce overfitting as no one single node in the layer will be responsible for predicting a certain class, object, edge, or corner.
From there we have two sets of (CONV => RELU) * 2 => POOL blocks:
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(64, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# (CONV => RELU) * 2 => POOL
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(Conv2D(128, (3, 3), padding="same"))
model.add(Activation("relu"))
model.add(BatchNormalization(axis=chanDim))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
Notice the numbers of filters, kernels, and pool sizes in this code block which work together to progressively reduce the spatial size but increase depth.
These blocks are followed by our only set of FC => RELU layers:
# first (and only) set of FC => RELU layers
model.add(Flatten())
model.add(Dense(1024))
model.add(Activation("relu"))
model.add(BatchNormalization())
model.add(Dropout(0.5))
# softmax classifier
model.add(Dense(classes))
model.add(Activation(finalAct))
# return the constructed network architecture
return model
Fully connected layers are placed at the end of the network (specified by Dense on Lines 57 and 63).
Line 64 is important for our multi-label classification — finalAct dictates whether we’ll use "softmax" activation for single-label classification or "sigmoid" activation in the case of today’s multi-label classification. Refer to Line 14 of this script, smallervggnet.py and Line 95 of train.py .
Implementing our Keras model for multi-label classification
Now that we have implemented SmallerVGGNet , let’s create train.py , the script we will use to train our Keras network for multi-label classification.
I urge you to review the previous post upon which today’s train.py script is based. In fact, you may want to view them on your screen side-by-side to see the difference and read full explanations. Today’s review will be succinct in comparison.
Open up train.py and insert the following code:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.model_selection import train_test_split
from pyimagesearch.smallervggnet import SmallerVGGNet
import matplotlib.pyplot as plt
from imutils import paths
import tensorflow as tf
import numpy as np
import argparse
import random
import pickle
import cv2
import os
On Lines 2-20 we import the packages and modules required for this script. Line 3 specifies a matplotlib backend so that we can save our plot figure in the background.
I’ll be making the assumption that you have Keras, scikit-learn, matpolotlib, imutils and OpenCV installed at this point. Be sure to refer to the “Configuring your development environment” section above.
Now that (a) your environment is ready, and (b) you’ve imported packages, let’s parse command line arguments:
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-d", "--dataset", required=True,
help="path to input dataset (i.e., directory of images)")
ap.add_argument("-m", "--model", required=True,
help="path to output model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to output label binarizer")
ap.add_argument("-p", "--plot", type=str, default="plot.png",
help="path to output accuracy/loss plot")
args = vars(ap.parse_args())
Command line arguments to a script are like parameters to a function — if you don’t understand this analogy then you need to read up on command line arguments.
We’re working with four command line arguments (Lines 23-32) today:
--dataset: The path to our dataset.--model: The path to our output serialized Keras model.--labelbin: The path to our output multi-label binarizer object.--plot: The path to our output plot of training loss and accuracy.
Be sure to refer to the previous post as needed for explanations of these arguments.
Let’s move on to initializing some important variables that play critical roles in our training process:
# initialize the number of epochs to train for, initial learning rate, # batch size, and image dimensions EPOCHS = 30 INIT_LR = 1e-3 BS = 32 IMAGE_DIMS = (96, 96, 3) # disable eager execution tf.compat.v1.disable_eager_execution()
These variables on Lines 36-39 define that:
- Our network will train for 75
EPOCHSin order to learn patterns by incremental improvements via backpropagation. - We’re establishing an initial learning rate of
1e-3(the default value for the Adam optimizer). - The batch size is
32. You should adjust this value depending on your GPU capability if you’re using a GPU but I found a batch size of32works well for this project. - As stated above, our images are
96 x 96and contain3channels.
Additional information on hyperparamters is provided in the previous post.
Line 42 disables TensorFlow’s Eager Execution mode. We found that this was necessary during our 2020-06-12 Update to achieve the same accuracy as on the original publication date of this article.
From there, the next two code blocks handle loading and preprocessing our training data:
# grab the image paths and randomly shuffle them
print("[INFO] loading images...")
imagePaths = sorted(list(paths.list_images(args["dataset"])))
random.seed(42)
random.shuffle(imagePaths)
# initialize the data and labels
data = []
labels = []
Here we are grabbing the imagePaths and shuffling them randomly, followed by initializing data and labels lists.
Next, we’re going to loop over the imagePaths , preprocess the image data, and extract multi-class-labels.
# loop over the input images
for imagePath in imagePaths:
# load the image, pre-process it, and store it in the data list
image = cv2.imread(imagePath)
image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
image = img_to_array(image)
data.append(image)
# extract set of class labels from the image path and update the
# labels list
l = label = imagePath.split(os.path.sep)[-2].split("_")
labels.append(l)
First, we load each image into memory (Line 57). Then, we perform preprocessing (an important step of the deep learning pipeline) on Lines 58 and 59. We append the image to data (Line 60).
Lines 64 and 65 handle splitting the image path into multiple labels for our multi-label classification task. After Line 64 is executed, a 2-element list is created and is then appended to the labels list on Line 65. Here’s an example broken down in the terminal so you can see what’s going on during the multi-label parsing:
$ python
>>> import os
>>> labels = []
>>> imagePath = "dataset/red_dress/long_dress_from_macys_red.png"
>>> l = label = imagePath.split(os.path.sep)[-2].split("_")
>>> l
['red', 'dress']
>>> labels.append(l)
>>>
>>> imagePath = "dataset/blue_jeans/stylish_blue_jeans_from_your_favorite_store.png"
>>> l = label = imagePath.split(os.path.sep)[-2].split("_")
>>> labels.append(l)
>>>
>>> imagePath = "dataset/red_shirt/red_shirt_from_target.png"
>>> l = label = imagePath.split(os.path.sep)[-2].split("_")
>>> labels.append(l)
>>>
>>> labels
[['red', 'dress'], ['blue', 'jeans'], ['red', 'shirt']]
As you can see, the labels list is a “list of lists” — each element of labels is a 2-element list. The two labels for each list is constructed based on the file path of the input image.
We’re not quite done with preprocessing:
# scale the raw pixel intensities to the range [0, 1]
data = np.array(data, dtype="float") / 255.0
labels = np.array(labels)
print("[INFO] data matrix: {} images ({:.2f}MB)".format(
len(imagePaths), data.nbytes / (1024 * 1000.0)))
Our data list contains images stored as NumPy arrays. In a single line of code, we convert the list to a NumPy array and scale the pixel intensities to the range [0, 1] .
We also convert labels to a NumPy array as well.
From there, let’s binarize the labels — the below block is critical for this week’s multi-class classification concept:
# binarize the labels using scikit-learn's special multi-label
# binarizer implementation
print("[INFO] class labels:")
mlb = MultiLabelBinarizer()
labels = mlb.fit_transform(labels)
# loop over each of the possible class labels and show them
for (i, label) in enumerate(mlb.classes_):
print("{}. {}".format(i + 1, label))
In order to binarize our labels for multi-class classification, we need to utilize the scikit-learn library’s MultiLabelBinarizer class. You cannot use the standard LabelBinarizer class for multi-class classification. Lines 76 and 77 fit and transform our human-readable labels into a vector that encodes which class(es) are present in the image.
Here’s an example showing how MultiLabelBinarizer transforms a tuple of ("red", "dress") to a vector with six total categories:
$ python
>>> from sklearn.preprocessing import MultiLabelBinarizer
>>> labels = [
... ("blue", "jeans"),
... ("blue", "dress"),
... ("red", "dress"),
... ("red", "shirt"),
... ("blue", "shirt"),
... ("black", "jeans")
... ]
>>> mlb = MultiLabelBinarizer()
>>> mlb.fit(labels)
MultiLabelBinarizer(classes=None, sparse_output=False)
>>> mlb.classes_
array(['black', 'blue', 'dress', 'jeans', 'red', 'shirt'], dtype=object)
>>> mlb.transform([("red", "dress")])
array([[0, 0, 1, 0, 1, 0]])
One-hot encoding transforms categorical labels from a single integer to a vector. The same concept applies to Lines 16 and 17 except this is a case of two-hot encoding.
Notice how on Line 17 of the Python shell (not to be confused with the code blocks for train.py ) two categorical labels are “hot” (represented by a “1” in the array), indicating the presence of each label. In this case “dress” and “red” are hot in the array (Lines 14-17). All other labels have a value of “0”.
Let’s construct the training and testing splits as well as initialize the data augmenter:
# partition the data into training and testing splits using 80% of # the data for training and the remaining 20% for testing (trainX, testX, trainY, testY) = train_test_split(data, labels, test_size=0.2, random_state=42) # construct the image generator for data augmentation aug = ImageDataGenerator(rotation_range=25, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode="nearest")
Splitting the data for training and testing is common in machine learning practice — I’ve allocated 80% of the images for training data and 20% for testing data. This is handled by scikit-learn on Lines 85 and 86.
Our data augmenter object is initialized on Lines 89-91. Data augmentation is a best practice and a most-likely a “must” if you are working with less than 1,000 images per class.
Next, let’s build the model and initialize the Adam optimizer:
# initialize the model using a sigmoid activation as the final layer
# in the network so we can perform multi-label classification
print("[INFO] compiling model...")
model = SmallerVGGNet.build(
width=IMAGE_DIMS[1], height=IMAGE_DIMS[0],
depth=IMAGE_DIMS[2], classes=len(mlb.classes_),
finalAct="sigmoid")
# initialize the optimizer (SGD is sufficient)
opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
On Lines 96-99 we build our SmallerVGGNet model, noting the finalAct="sigmoid" parameter indicating that we’ll be performing multi-label classification.
From there, we’ll compile the model and kick off training (this could take a while depending on your hardware):
# compile the model using binary cross-entropy rather than
# categorical cross-entropy -- this may seem counterintuitive for
# multi-label classification, but keep in mind that the goal here
# is to treat each output label as an independent Bernoulli
# distribution
model.compile(loss="binary_crossentropy", optimizer=opt,
metrics=["accuracy"])
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=BS),
validation_data=(testX, testY),
steps_per_epoch=len(trainX) // BS,
epochs=EPOCHS, verbose=1)
2020-06-12 Update: Formerly, TensorFlow/Keras required use of a method called .fit_generator in order to accomplish data augmentation. Now, the .fit method can handle data augmentation as well, making for more-consistent code. This also applies to the migration from .predict_generator to .predict. Be sure to check out my articles about fit and fit_generator as well as data augmentation.
On Lines 109 and 110 we compile the model using binary cross-entropy rather than categorical cross-entropy.
This may seem counterintuitive for multi-label classification; however, the goal is to treat each output label as an independent Bernoulli distribution and we want to penalize each output node independently.
From there we launch the training process with our data augmentation generator (Lines 114-118).
After training is complete we can save our model and label binarizer to disk:
# save the model to disk
print("[INFO] serializing network...")
model.save(args["model"], save_format="h5")
# save the multi-label binarizer to disk
print("[INFO] serializing label binarizer...")
f = open(args["labelbin"], "wb")
f.write(pickle.dumps(mlb))
f.close()
2020-06-12 Update: Note that for TensorFlow 2.0+ we recommend explicitly setting the save_format="h5" (HDF5 format).
From there, we plot accuracy and loss:
# plot the training loss and accuracy
plt.style.use("ggplot")
plt.figure()
N = EPOCHS
plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0, N), H.history["accuracy"], label="train_acc")
plt.plot(np.arange(0, N), H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="upper left")
plt.savefig(args["plot"])
2020-06-12 Update: In order for this plotting snippet to be TensorFlow 2+ compatible the H.history dictionary keys are updated to fully spell out “accuracy” sans “acc” (i.e., H.history["val_accuracy"] and H.history["accuracy"]). It is semi-confusing that “val” is not spelled out as “validation”; we have to learn to love and live with the API and always remember that it is a work in progress that many developers around the world contribute to.
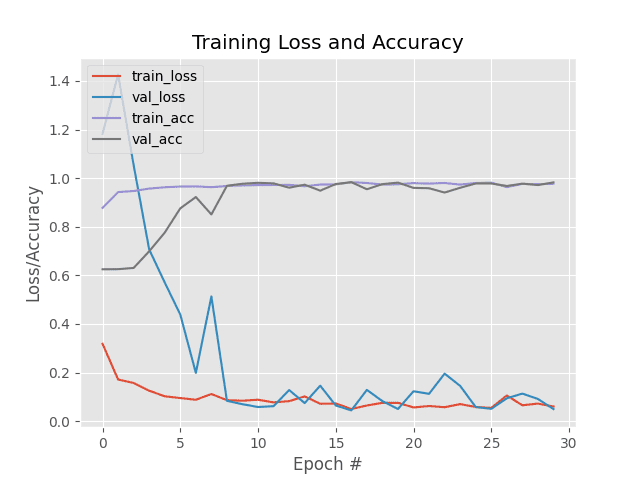
Accuracy + loss for training and validation is plotted on Lines 131-141. The plot is saved as an image file on Line 142.
In my opinion, the training plot is just as important as the model itself. I typically go through a few iterations of training and viewing the plot before I’m satisfied to share with you on the blog.
I like to save plots to disk during this iterative process for a couple reasons: (1) I’m on a headless server and don’t want to rely on X-forwarding, and (2) I don’t want to forget to save the plot (even if I am using X-forwarding or if I’m on a machine with a graphical desktop).
Recall that we changed the matplotlib backend on Line 3 of the script up above to facilitate saving to disk.
Training a Keras network for multi-label classification
Don’t forget to use the “Downloads” section of this post to download the code, dataset, and pre-trained model (just in case you don’t want to train the model yourself).
If you want to train the model yourself, open a terminal. From there, navigate to the project directory, and execute the following command:
$ python train.py --dataset dataset --model fashion.model \ --labelbin mlb.pickle Using TensorFlow backend. [INFO] loading images... [INFO] data matrix: 2165 images (467.64MB) [INFO] class labels: 1. black 2. blue 3. dress 4. jeans 5. red 6. shirt [INFO] compiling model... [INFO] training network... Epoch 1/30 54/54 [==============================] - 2s 35ms/step - loss: 0.3184 - accuracy: 0.8774 - val_loss: 1.1824 - val_accuracy: 0.6251 Epoch 2/30 54/54 [==============================] - 2s 37ms/step - loss: 0.1881 - accuracy: 0.9427 - val_loss: 1.4268 - val_accuracy: 0.6255 Epoch 3/30 54/54 [==============================] - 2s 38ms/step - loss: 0.1551 - accuracy: 0.9471 - val_loss: 1.0533 - val_accuracy: 0.6305 ... Epoch 28/30 54/54 [==============================] - 2s 41ms/step - loss: 0.0656 - accuracy: 0.9763 - val_loss: 0.1137 - val_accuracy: 0.9773 Epoch 29/30 54/54 [==============================] - 2s 40ms/step - loss: 0.0801 - accuracy: 0.9751 - val_loss: 0.0916 - val_accuracy: 0.9715 Epoch 30/30 54/54 [==============================] - 2s 37ms/step - loss: 0.0636 - accuracy: 0.9770 - val_loss: 0.0500 - val_accuracy: 0.9823 [INFO] serializing network... [INFO] serializing label binarizer...
As you can see, we trained the network for 30 epochs, achieving:
- 97.70% multi-label classification accuracy on the training set
- 98.23% multi-label classification accuracy on the testing set
The training plot is shown in Figure 3:
Applying Keras multi-label classification to new images
Now that our multi-label classification Keras model is trained, let’s apply it to images outside of our testing set.
This script is quite similar to the classify.py script in my previous post — be sure to look out for the multi-label differences.
When you’re ready, open create a new file in the project directory named classify.py and insert the following code (or follow along with the file included with the “Downloads”):
# import the necessary packages
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
import numpy as np
import argparse
import imutils
import pickle
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-m", "--model", required=True,
help="path to trained model model")
ap.add_argument("-l", "--labelbin", required=True,
help="path to label binarizer")
ap.add_argument("-i", "--image", required=True,
help="path to input image")
args = vars(ap.parse_args())
On Lines 2-9 we import the necessary packages for this script. Notably, we’ll be using Keras and OpenCV in this script.
Then we proceed to parse our three required command line arguments on Lines 12-19.
From there, we load and preprocess the input image:
# load the image
image = cv2.imread(args["image"])
output = imutils.resize(image, width=400)
# pre-process the image for classification
image = cv2.resize(image, (96, 96))
image = image.astype("float") / 255.0
image = img_to_array(image)
image = np.expand_dims(image, axis=0)
We take care to preprocess the image in the same manner as we preprocessed our training data.
Next, let’s load the model + multi-label binarizer and classify the image:
# load the trained convolutional neural network and the multi-label
# binarizer
print("[INFO] loading network...")
model = load_model(args["model"])
mlb = pickle.loads(open(args["labelbin"], "rb").read())
# classify the input image then find the indexes of the two class
# labels with the *largest* probability
print("[INFO] classifying image...")
proba = model.predict(image)[0]
idxs = np.argsort(proba)[::-1][:2]
We load the model and multi-label binarizer from disk into memory on Lines 34 and 35.
From there we classify the (preprocessed) input image (Line 40) and extract the top two class labels indices (Line 41) by:
- Sorting the array indexes by their associated probability in descending order
- Grabbing the first two class label indices which are thus the top-2 predictions from our network
You can modify this code to return more class labels if you wish. I would also suggest thresholding the probabilities and only returning labels with > N% confidence.
From there, we’ll prepare the class labels + associated confidence values for overlay on the output image:
# loop over the indexes of the high confidence class labels
for (i, j) in enumerate(idxs):
# build the label and draw the label on the image
label = "{}: {:.2f}%".format(mlb.classes_[j], proba[j] * 100)
cv2.putText(output, label, (10, (i * 30) + 25),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# show the probabilities for each of the individual labels
for (label, p) in zip(mlb.classes_, proba):
print("{}: {:.2f}%".format(label, p * 100))
# show the output image
cv2.imshow("Output", output)
cv2.waitKey(0)
The loop on Lines 44-48 draws the top two multi-label predictions and corresponding confidence values on the output image.
Similarly, the loop on Lines 51 and 52 prints the all the predictions in the terminal. This is useful for debugging purposes.
Finally, we show the output image on the screen (Lines 55 and 56).
Keras multi-label classification results
Let’s put classify.py to work using command line arguments. You do not need to modify the code discussed above in order to pass new images through the CNN. Simply use the command line arguments in your terminal as is shown below.
Let’s try an image of a red dress — notice the three command line arguments that are processed at runtime:
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_01.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 0.00% blue: 3.58% dress: 95.14% jeans: 0.00% red: 100.00% shirt: 64.02%

Success! Notice how the two classes (“red” and “dress”) are marked with high confidence.
Now let’s try a blue dress:
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_02.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 0.03% blue: 99.98% dress: 98.50% jeans: 0.23% red: 0.00% shirt: 0.74%

A blue dress was no contest for our classifier. We’re off to a good start, so let’s try an image of a red shirt:
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_03.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 0.00% blue: 0.69% dress: 0.00% jeans: 0.00% red: 100.00% shirt: 100.00%

The red shirt result is promising.
How about a blue shirt?
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_04.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 0.00% blue: 99.99% dress: 22.59% jeans: 0.08% red: 0.00% shirt: 82.82%

Our model is very confident that it sees blue, but slightly less confident that it has encountered a shirt. That being said, this is still a correct multi-label classification!
Let’s see if we can fool our multi-label classifier with blue jeans:
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_05.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 0.00% blue: 100.00% dress: 0.01% jeans: 99.99% red: 0.00% shirt: 0.00%

Let’s try black jeans:
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_06.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 100.00% blue: 0.00% dress: 0.01% jeans: 100.00% red: 0.00% shirt: 0.00%

I can’t be 100% sure that these are denim jeans (they look more like leggings/jeggings to me), but our multi-label classifier is!
Let’s try a final example of a black dress (example_07.jpg ). While our network has learned to predict “black jeans” and “blue jeans” along with both “blue dress” and “red dress”, can it be used to classify a “black dress”?
$ python classify.py --model fashion.model --labelbin mlb.pickle \ --image examples/example_07.jpg Using TensorFlow backend. [INFO] loading network... [INFO] classifying image... black: 91.28% blue: 7.70% dress: 5.48% jeans: 71.87% red: 0.00% shirt: 5.92%

Oh no — a blunder! Our classifier is reporting that the model is wearing black jeans when she is actually wearing a black dress.
What happened here?
Why are our multi-class predictions incorrect? To find out why, review the summary below.
What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In today’s blog post you learned how to perform multi-label classification with Keras.
Performing multi-label classification with Keras is straightforward and includes two primary steps:
- Replace the softmax activation at the end of your network with a sigmoid activation
- Swap out categorical cross-entropy for binary cross-entropy for your loss function
From there you can train your network as you normally would.
The end result of applying the process above is a multi-class classifier.
You can use your Keras multi-class classifier to predict multiple labels with just a single forward pass.
However, there is a difficulty you need to consider:
You need training data for each combination of categories you would like to predict.
Just like a neural network cannot predict classes it was never trained on, your neural network cannot predict multiple class labels for combinations it has never seen. The reason for this behavior is due to activations of neurons inside the network.
If your network is trained on examples of both (1) black pants and (2) red shirts and now you want to predict “red pants” (where there are no “red pants” images in your dataset), the neurons responsible for detecting “red” and “pants” will fire, but since the network has never seen this combination of data/activations before once they reach the fully-connected layers, your output predictions will very likely be incorrect (i.e., you may encounter “red” or “pants” but very unlikely both).
Again, your network cannot correctly make predictions on data it was never trained on (and you shouldn’t expect it to either). Keep this caveat in mind when training your own Keras networks for multi-label classification.
I hope you enjoyed this post!
To be notified when future posts are published here on PyImageSearch, just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

