
In this tutorial, you will learn about learning rate schedules and decay using Keras. You’ll learn how to use Keras’ standard learning rate decay along with step-based, linear, and polynomial learning rate schedules.
When training a neural network, the learning rate is often the most important hyperparameter for you to tune:
- Too small a learning rate and your neural network may not learn at all
- Too large a learning rate and you may overshoot areas of low loss (or even overfit from the start of training)
When it comes to training a neural network, the most bang for your buck (in terms of accuracy) is going to come from selecting the correct learning rate and appropriate learning rate schedule.
But that’s easier said than done.
To help deep learning practitioners such as yourself learn how to assess a problem and choose an appropriate learning rate, we’ll be starting a series of tutorials on learning rate schedules, decay, and hyperparameter tuning with Keras.
By the end of this series, you’ll have a good understanding of how to appropriately and effectively apply learning rate schedules with Keras to your own deep learning projects.
To learn how to use Keras for learning rate schedules and decay, just keep reading
Keras learning rate schedules and decay
2020-06-11 Update: This blog post is now TensorFlow 2+ compatible!
In the first part of this guide, we’ll discuss why the learning rate is the most important hyperparameter when it comes to training your own deep neural networks.
We’ll then dive into why we may want to adjust our learning rate during training.
From there I’ll show you how to implement and utilize a number of learning rate schedules with Keras, including:
- The decay schedule built into most Keras optimizers
- Step-based learning rate schedules
- Linear learning rate decay
- Polynomial learning rate schedules
We’ll then perform a number of experiments on the CIFAR-10 using these learning rate schedules and evaluate which one performed the best.
These sets of experiments will serve as a template you can use when exploring your own deep learning projects and selecting an appropriate learning rate and learning rate schedule.
Why adjust our learning rate and use learning rate schedules?
To see why learning rate schedules are a worthwhile method to apply to help increase model accuracy and descend into areas of lower loss, consider the standard weight update formula used by nearly all neural networks:

Recall that the learning rate,  , controls the “step” we make along the gradient. Larger values of imply that we are taking bigger steps. While smaller values of will make tiny steps. If is zero the network cannot make any steps at all (since the gradient multiplied by zero is zero).
, controls the “step” we make along the gradient. Larger values of imply that we are taking bigger steps. While smaller values of will make tiny steps. If is zero the network cannot make any steps at all (since the gradient multiplied by zero is zero).
Most initial learning rates (but not all) you encounter are typically in the set  .
.
A network is then trained for a fixed number of epochs without changing the learning rate.
This method may work well in some situations, but it’s often beneficial to decrease our learning rate over time. When training our network, we are trying to find some location along our loss landscape where the network obtains reasonable accuracy. It doesn’t have to be a global minima or even a local minima, but in practice, simply finding an area of the loss landscape with reasonably low loss is “good enough”.
If we constantly keep a learning rate high, we could overshoot these areas of low loss as we’ll be taking too large of steps to descend into those series.
Instead, what we can do is decrease our learning rate, thereby allowing our network to take smaller steps — this decreased learning rate enables our network to descend into areas of the loss landscape that are “more optimal” and would have otherwise been missed entirely by our learning rate learning.
We can, therefore, view the process of learning rate scheduling as:
- Finding a set of reasonably “good” weights early in the training process with a larger learning rate.
- Tuning these weights later in the process to find more optimal weights using a smaller learning rate.
We’ll be covering some of the most popular learning rate schedules in this tutorial.
Configuring your development environment
To configure your system for this tutorial, I first recommend following either of these tutorials:
Either tutorial will help you configure you system with all the necessary software for this blog post in a convenient Python virtual environment.
Please note that PyImageSearch does not recommend or support Windows for CV/DL projects.
Project structure
Once you’ve grabbed and extracted the “Downloads” go ahead and use the tree command to inspect the project folder:
$ tree . ├── output │ ├── lr_linear_schedule.png │ ├── lr_poly_schedule.png │ ├── lr_step_schedule.png │ ├── train_linear_schedule.png │ ├── train_no_schedule.png │ ├── train_poly_schedule.png │ ├── train_standard_schedule.png │ └── train_step_schedule.png ├── pyimagesearch │ ├── __init__.py │ ├── learning_rate_schedulers.py │ └── resnet.py └── train.py 2 directories, 12 files
Our output/ directory will contain learning rate and training history plots. The five experiments included in the results section correspond to the five plots with the train_*.png filenames, respectively.
The pyimagesearch module contains our ResNet CNN and our learning_rate_schedulers.py . The LearningRateDecay parent class simply includes a method called plot for plotting each of our types of learning rate decay. Also included are subclasses, StepDecay and PolynomialDecay which calculate the learning rate upon the completion of each epoch. Both of these classes contain the plot method via inheritance (an object-oriented concept).
Our training script, train.py , will train ResNet on the CIFAR-10 dataset. We’ll run the script with the absence of learning rate decay as well as standard, linear, step-based, and polynomial learning rate decay.
The standard “decay” schedule in Keras
The Keras library ships with a time-based learning rate scheduler — it is controlled via the decay parameter of the optimizer class (such as SGD, Adam, etc.).
To discover how we can utilize this type of learning rate decay, let’s take a look at an example of how we may initialize the ResNet architecture and the SGD optimizer:
# initialize our optimizer and model, then compile it opt = SGD(lr=1e-2, momentum=0.9, decay=1e-2/epochs) model = ResNet.build(32, 32, 3, 10, (9, 9, 9), (64, 64, 128, 256), reg=0.0005) model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
Here we initialize our SGD optimizer with an initial learning rate of 1e-2 . We then set our decay to be the learning rate divided by the total number of epochs we are training the network for (a common rule of thumb).
Internally, Keras applies the following learning rate schedule to adjust the learning rate after every batch update — it is a misconception that Keras updates the standard decay after every epoch. Keep this in mind when using the default learning rate scheduler supplied with Keras.
The update formula follows: 
Using the CIFAR-10 dataset as an example, we have a total of 50,000 training images.
If we use a batch size of 64 , that implies there are a total of  steps per epoch. Therefore, a total of
steps per epoch. Therefore, a total of 782 weight updates need to be applied before an epoch completes.
To see an example of the learning rate schedule calculation, let’s assume our initial learning rate is  and our
and our  (with the assumption that we are training for forty epochs).
(with the assumption that we are training for forty epochs).
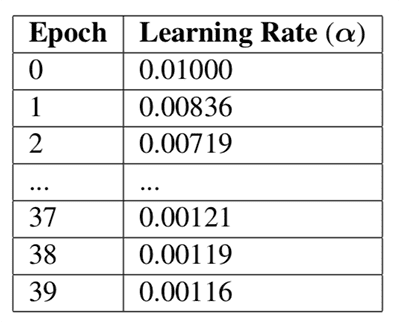
The learning rate at step zero, before any learning rate schedule has been applied, is:
} = 0.01")
At the beginning of epoch one we can see the following learning rate:
} = 0.00836")
Figure 1 below continues the calculation of Keras’ standard learning rate decay  and a decay of
and a decay of  :
:
You’ll learn how to utilize this type of learning rate decay inside the “Implementing our training script” and “Keras learning rate schedule results” sections of this post, respectively.
Our LearningRateDecay class
In the remainder of this tutorial, we’ll be implementing our own custom learning rate schedules and then incorporating them with Keras when training our neural networks.
To keep our code neat and tidy, and not to mention, follow object-oriented programming best practices, let’s first define a base LearningRateDecay class that we’ll subclass for each respective learning rate schedule.
Open up the learning_rate_schedulers.py in your directory structure and insert the following code:
# import the necessary packages
import matplotlib.pyplot as plt
import numpy as np
class LearningRateDecay:
def plot(self, epochs, title="Learning Rate Schedule"):
# compute the set of learning rates for each corresponding
# epoch
lrs = [self(i) for i in epochs]
# the learning rate schedule
plt.style.use("ggplot")
plt.figure()
plt.plot(epochs, lrs)
plt.title(title)
plt.xlabel("Epoch #")
plt.ylabel("Learning Rate")
Each and every learning rate schedule we implement will have a plot function, enabling us to visualize our learning rate over time.
With our base LearningRateSchedule class implement, let’s move on to creating a step-based learning rate schedule.
Step-based learning rate schedules with Keras
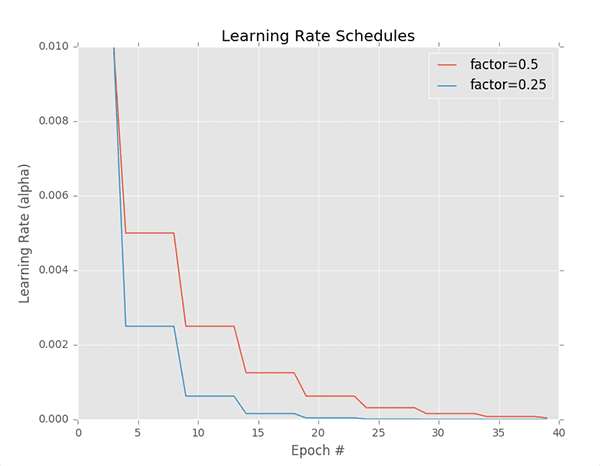
One popular learning rate scheduler is step-based decay where we systematically drop the learning rate after specific epochs during training.
The step decay learning rate scheduler can be seen as a piecewise function, as visualized in Figure 2 — here the learning rate is constant for a number of epochs, then drops, is constant once more, then drops again, etc.
When applying step decay to our learning rate, we have two options:
- Define an equation that models the piecewise drop-in learning rate that we wish to achieve.
- Use what I call the
ctrl + cmethod to train a deep neural network. Here we train for some number of epochs at a given learning rate and eventually notice validation performance stagnating/stalling, thenctrl + cto stop the script, adjust our learning rate, and continue training.
We’ll primarily be focusing on the equation-based piecewise drop to learning rate scheduling in this post.
The ctrl + c method is a bit more advanced and normally applied to larger datasets using deeper neural networks where the exact number of epochs required to obtain a reasonable model is unknown.
If you’d like to learn more about the ctrl + c method to training, please refer to Deep Learning for Computer Vision with Python.
When applying step decay, we often drop our learning rate by either (1) half or (2) an order of magnitude after every fixed number of epochs. For example, let’s suppose our initial learning rate is .
After 10 epochs we drop the learning rate to  .
.
After another 10 epochs (i.e., the 20th total epoch), is dropped by a factor of 0.5 again, such that  , etc.
, etc.
In fact, this is the exact same learning rate schedule that is depicted in Figure 2 (red line).
The blue line displays a more aggressive drop factor of 0.25 . Modeled mathematically, we can define our step-based decay equation as:
 / D}")
Where  is the initial learning rate,
is the initial learning rate,  is the factor value controlling the rate in which the learning date drops, D is the “Drop every” epochs value, and E is the current epoch.
is the factor value controlling the rate in which the learning date drops, D is the “Drop every” epochs value, and E is the current epoch.
The larger our factor is, the slower the learning rate will decay.
Conversely, the smaller the factor , the faster the learning rate will decay.
All that said, let’s go ahead and implement our StepDecay class now.
Go back to your learning_rate_schedulers.py file and insert the following code:
class StepDecay(LearningRateDecay): def __init__(self, initAlpha=0.01, factor=0.25, dropEvery=10): # store the base initial learning rate, drop factor, and # epochs to drop every self.initAlpha = initAlpha self.factor = factor self.dropEvery = dropEvery def __call__(self, epoch): # compute the learning rate for the current epoch exp = np.floor((1 + epoch) / self.dropEvery) alpha = self.initAlpha * (self.factor ** exp) # return the learning rate return float(alpha)
Line 20 defines the constructor to our StepDecay class. We then store the initial learning rate (initAlpha ), drop factor, and dropEvery epochs values (Lines 23-25).
The __call__ function:
- Accepts the current
epochnumber. - Computes the learning rate based on the step-based decay formula detailed above (Lines 29 and 30).
- Returns the computed learning rate for the current epoch (Line 33).
You’ll see how to use this learning rate schedule later in this post.
Linear and polynomial learning rate schedules in Keras
Two of my favorite learning rate schedules are linear learning rate decay and polynomial learning rate decay.
Using these methods our learning rate is decayed to zero over a fixed number of epochs.
The rate in which the learning rate is decayed is based on the parameters to the polynomial function. A smaller exponent/power to the polynomial will cause the learning rate to decay “more slowly”, whereas larger exponents decay the learning rate “more quickly”.
Conveniently, both of these methods can be implemented in a single class:
class PolynomialDecay(LearningRateDecay): def __init__(self, maxEpochs=100, initAlpha=0.01, power=1.0): # store the maximum number of epochs, base learning rate, # and power of the polynomial self.maxEpochs = maxEpochs self.initAlpha = initAlpha self.power = power def __call__(self, epoch): # compute the new learning rate based on polynomial decay decay = (1 - (epoch / float(self.maxEpochs))) ** self.power alpha = self.initAlpha * decay # return the new learning rate return float(alpha)
Line 36 defines the constructor to our PolynomialDecay class which requires three values:
maxEpochs: The total number of epochs we’ll be training for.initAlpha: The initial learning rate.power: The power/exponent of the polynomial.
Note that if you set power=1.0 then you have a linear learning rate decay.
Lines 45 and 46 compute the adjusted learning rate for the current epoch while Line 49 returns the new learning rate.
Implementing our training script
Now that we’ve implemented a few different Keras learning rate schedules, let’s see how we can use them inside an actual training script.
Create a file named train.py file in your editor and insert the following code:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.learning_rate_schedulers import StepDecay
from pyimagesearch.learning_rate_schedulers import PolynomialDecay
from pyimagesearch.resnet import ResNet
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
import argparse
Lines 2-16 import required packages. Line 3 sets the matplotlib backend so that we can create plots as image files. Our most notable imports include:
StepDecay: Our class which calculates and plots step-based learning rate decay.PolynomialDecay: The class we wrote to calculate polynomial-based learning rate decay.ResNet: Our Convolutional Neural Network implemented in Keras.LearningRateScheduler: A Keras callback. We’ll pass our learning ratescheduleto this class which will be called as a callback at the completion of each epoch to calculate our learning rate.
Let’s move on and parse our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-s", "--schedule", type=str, default="",
help="learning rate schedule method")
ap.add_argument("-e", "--epochs", type=int, default=100,
help="# of epochs to train for")
ap.add_argument("-l", "--lr-plot", type=str, default="lr.png",
help="path to output learning rate plot")
ap.add_argument("-t", "--train-plot", type=str, default="training.png",
help="path to output training plot")
args = vars(ap.parse_args())
Our script accepts any of four command line arguments when the script is called via the terminal:
--schedule: The learning rate schedule method. Valid options are “standard”, “step”, “linear”, “poly”. By default, no learning rate schedule will be used.--epochs: The number of epochs to train for (default=100).--lr-plot: The path to the output plot. I suggest overriding thedefaultoflr.pngwith a more descriptive path + filename.--train-plot: The path to the output accuracy/loss training history plot. Again, I suggest a descriptive path + filename, otherwisetraining.pngwill be set bydefault.
With our imports and command line arguments in hand, now it’s time to initialize our learning rate schedule:
# store the number of epochs to train for in a convenience variable,
# then initialize the list of callbacks and learning rate scheduler
# to be used
epochs = args["epochs"]
callbacks = []
schedule = None
# check to see if step-based learning rate decay should be used
if args["schedule"] == "step":
print("[INFO] using 'step-based' learning rate decay...")
schedule = StepDecay(initAlpha=1e-1, factor=0.25, dropEvery=15)
# check to see if linear learning rate decay should should be used
elif args["schedule"] == "linear":
print("[INFO] using 'linear' learning rate decay...")
schedule = PolynomialDecay(maxEpochs=epochs, initAlpha=1e-1, power=1)
# check to see if a polynomial learning rate decay should be used
elif args["schedule"] == "poly":
print("[INFO] using 'polynomial' learning rate decay...")
schedule = PolynomialDecay(maxEpochs=epochs, initAlpha=1e-1, power=5)
# if the learning rate schedule is not empty, add it to the list of
# callbacks
if schedule is not None:
callbacks = [LearningRateScheduler(schedule)]
Line 33 sets the number of epochs we will train for directly from the command line args variable. From there we’ll initialize our callbacks list and learning rate schedule (Lines 34 and 35).
Lines 38-50 then select the learning rate schedule if args["schedule"] contains a valid value:
"step": InitializesStepDecay."linear": InitializesPolynomialDecaywithpower=1indicating that a linear learning rate decay will be utilized."poly":PolynomialDecaywith apower=5will be used.
After you’ve reproduced the results of the experiments in this tutorial, be sure to revisit Lines 38-50 and insert additional elif statements of your own so you can run some of your own experiments!
Lines 54 and 55 initialize the LearningRateScheduler with the schedule as a single callback part of the callbacks list. There is a case where no learning rate decay will be used (i.e. if the --schedule command line argument is not overridden when the script is executed).
Let’s go ahead and load our data:
# load the training and testing data, then scale it into the
# range [0, 1]
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float") / 255.0
testX = testX.astype("float") / 255.0
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# initialize the label names for the CIFAR-10 dataset
labelNames = ["airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"]
Line 60 loads our CIFAR-10 data. The dataset is conveniently already split into training and testing sets.
The only preprocessing we must perform is to scale the data into the range [0, 1] (Lines 61 and 62).
Lines 65-67 binarize the labels and then Lines 70 and 71 initialize our labelNames (i.e. classes). Do not add to or alter the labelNames list as order and length of the list matter.
Let’s initialize decay parameter:
# initialize the decay for the optimizer
decay = 0.0
# if we are using Keras' "standard" decay, then we need to set the
# decay parameter
if args["schedule"] == "standard":
print("[INFO] using 'keras standard' learning rate decay...")
decay = 1e-1 / epochs
# otherwise, no learning rate schedule is being used
elif schedule is None:
print("[INFO] no learning rate schedule being used")
Line 74 initializes our learning rate decay .
If we’re using the "standard" learning rate decay schedule, then the decay is initialized as 1e-1 / epochs (Lines 78-80).
With all of our initializations taken care of, let’s go ahead and compile + train our ResNet model:
# initialize our optimizer and model, then compile it opt = SGD(lr=1e-1, momentum=0.9, decay=decay) model = ResNet.build(32, 32, 3, 10, (9, 9, 9), (64, 64, 128, 256), reg=0.0005) model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"]) # train the network H = model.fit(x=trainX, y=trainY, validation_data=(testX, testY), batch_size=128, epochs=epochs, callbacks=callbacks, verbose=1)
Our Stochastic Gradient Descent (SGD ) optimizer is initialized on Line 87 using our decay .
From there, Lines 88 and 89 build our ResNet CNN with an input shape of 32x32x3 and 10 classes. For an in-depth review of ResNet, be sure refer to Chapter 10: ResNet of Deep Learning for Computer Vision with Python.
Our model is compiled with a loss function of "categorical_crossentropy" since our dataset has > 2 classes. If you use a different dataset with only 2 classes, be sure to use loss="binary_crossentropy" .
Lines 94 and 95 kick of our training process. Notice that we’ve provided the callbacks as a parameter. The callbacks will be called when each epoch is completed. Our LearningRateScheduler contained therein will handle our learning rate decay (so long as callbacks isn’t an empty list).
Finally, let’s evaluate our network and generate plots:
# evaluate the network
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=128)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=labelNames))
# plot the training loss and accuracy
N = np.arange(0, args["epochs"])
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy on CIFAR-10")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.savefig(args["train_plot"])
# if the learning rate schedule is not empty, then save the learning
# rate plot
if schedule is not None:
schedule.plot(N)
plt.savefig(args["lr_plot"])
2020-06-11 Update: In order for this plotting snippet to be TensorFlow 2+ compatible the H.history dictionary keys are updated to fully spell out “accuracy” sans “acc” (i.e., H.history["val_accuracy"] and H.history["accuracy"]). It is semi-confusing that “val” is not spelled out as “validation”; we have to learn to love and live with the API and always remember that it is a work in progress that many developers around the world contribute to.
Lines 99-101 evaluate our network and print a classification report to our terminal.
Lines 104-115 generate and save our training history plot (accuracy/loss curves). Lines 119-121 generate a learning rate schedule plot, if applicable. We will inspect these plot visualizations in the next section.
Keras learning rate schedule results
With both our (1) learning rate schedules and (2) training scripts implemented, let’s run some experiments to see which learning rate schedule will perform best given:
- An initial learning rate of
1e-1 - Training for a total of
100epochs
Experiment #1: No learning rate decay/schedule
As a baseline, let’s first train our ResNet model on CIFAR-10 with no learning rate decay or schedule:
$ python train.py --train-plot output/train_no_schedule.png
[INFO] loading CIFAR-10 data...
[INFO] no learning rate schedule being used
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.0893 - accuracy: 0.4525 - val_loss: 1.7665 - val_accuracy: 0.5566
Epoch 2/100
391/391 [==============================] - 34s 88ms/step - loss: 1.4742 - accuracy: 0.6599 - val_loss: 1.4228 - val_accuracy: 0.6673
Epoch 3/100
391/391 [==============================] - 33s 86ms/step - loss: 1.1942 - accuracy: 0.7456 - val_loss: 1.4430 - val_accuracy: 0.6697
...
Epoch 98/100
391/391 [==============================] - 33s 86ms/step - loss: 0.5259 - accuracy: 0.9554 - val_loss: 1.0222 - val_accuracy: 0.8232
Epoch 99/100
391/391 [==============================] - 34s 86ms/step - loss: 0.5176 - accuracy: 0.9570 - val_loss: 0.9845 - val_accuracy: 0.8386
Epoch 100/100
391/391 [==============================] - 34s 86ms/step - loss: 0.5328 - accuracy: 0.9516 - val_loss: 0.9788 - val_accuracy: 0.8414
[INFO] evaluating network...
precision recall f1-score support
airplane 0.84 0.88 0.86 1000
automobile 0.92 0.94 0.93 1000
bird 0.85 0.74 0.79 1000
cat 0.67 0.77 0.72 1000
deer 0.80 0.87 0.83 1000
dog 0.89 0.64 0.74 1000
frog 0.90 0.86 0.88 1000
horse 0.76 0.95 0.84 1000
ship 0.92 0.90 0.91 1000
truck 0.94 0.85 0.90 1000
accuracy 0.84 10000
macro avg 0.85 0.84 0.84 10000
weighted avg 0.85 0.84 0.84 10000
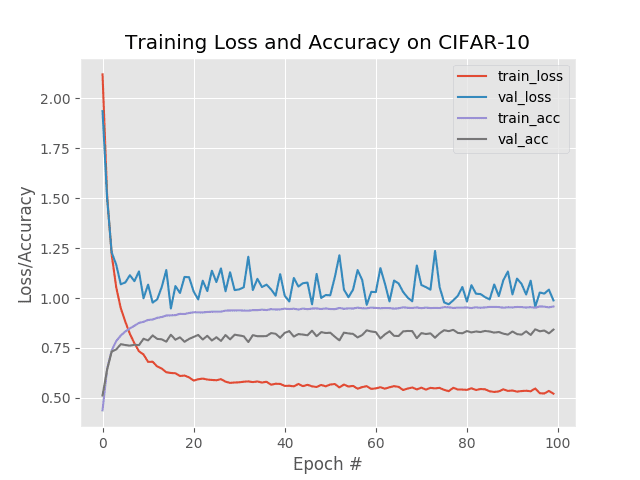
Here we obtain ~85% accuracy, but as we can see, validation loss and accuracy stagnate past epoch ~15 and do not improve over the rest of the 100 epochs.
Our goal is now to utilize learning rate scheduling to beat our 85% accuracy (without overfitting).
Experiment: #2: Keras standard optimizer learning rate decay
In our second experiment we are going to use Keras’ standard decay-based learning rate schedule:
$ python train.py --schedule standard --train-plot output/train_standard_schedule.png
[INFO] loading CIFAR-10 data...
[INFO] using 'keras standard' learning rate decay...
Epoch 1/100
391/391 [==============================] - 37s 95ms/step - loss: 2.0800 - accuracy: 0.4342 - val_loss: 1.8035 - val_accuracy: 0.5263
Epoch 2/100
391/391 [==============================] - 34s 87ms/step - loss: 1.5053 - accuracy: 0.6380 - val_loss: 1.4067 - val_accuracy: 0.6742
Epoch 3/100
391/391 [==============================] - 34s 86ms/step - loss: 1.2313 - accuracy: 0.7293 - val_loss: 1.3025 - val_accuracy: 0.7043
...
Epoch 98/100
391/391 [==============================] - 34s 87ms/step - loss: 0.1746 - accuracy: 1.0000 - val_loss: 0.9269 - val_accuracy: 0.8112
Epoch 99/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1741 - accuracy: 0.9999 - val_loss: 0.9301 - val_accuracy: 0.8123
Epoch 100/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1732 - accuracy: 1.0000 - val_loss: 0.9210 - val_accuracy: 0.8151
[INFO] evaluating network...
precision recall f1-score support
airplane 0.84 0.84 0.84 1000
automobile 0.89 0.92 0.91 1000
bird 0.72 0.76 0.74 1000
cat 0.67 0.65 0.66 1000
deer 0.78 0.78 0.78 1000
dog 0.75 0.73 0.74 1000
frog 0.85 0.85 0.85 1000
horse 0.87 0.83 0.85 1000
ship 0.89 0.92 0.90 1000
truck 0.88 0.88 0.88 1000
accuracy 0.82 10000
macro avg 0.81 0.82 0.81 10000
weighted avg 0.81 0.82 0.81 10000
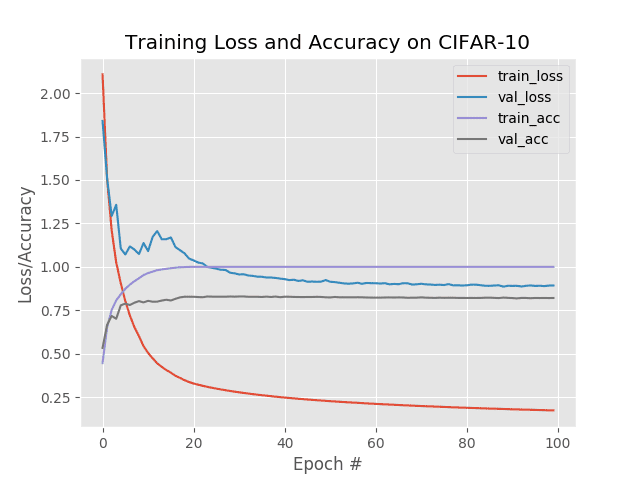
This time we only obtain 81% accuracy, which goes to show, learning rate decay/scheduling will not always improve your results! You need to be careful which learning rate schedule you utilize.
Experiment #3: Step-based learning rate schedule results
Let’s go ahead and perform step-based learning rate scheduling which will drop our learning rate by a factor of 0.25 every 15 epochs:
$ python train.py --schedule step --lr-plot output/lr_step_schedule.png --train-plot output/train_step_schedule.png
[INFO] using 'step-based' learning rate decay...
[INFO] loading CIFAR-10 data...
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.1558 - accuracy: 0.4447 - val_loss: 1.7844 - val_accuracy: 0.5635 - lr: 0.1000
Epoch 2/100
391/391 [==============================] - 34s 86ms/step - loss: 1.5154 - accuracy: 0.6567 - val_loss: 1.5359 - val_accuracy: 0.6482 - lr: 0.1000
Epoch 3/100
391/391 [==============================] - 33s 86ms/step - loss: 1.2203 - accuracy: 0.7384 - val_loss: 1.3994 - val_accuracy: 0.6768 - lr: 0.1000
...
Epoch 98/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1821 - accuracy: 1.0000 - val_loss: 0.7240 - val_accuracy: 0.8679 - lr: 2.4414e-05
Epoch 99/100
391/391 [==============================] - 33s 85ms/step - loss: 0.1820 - accuracy: 1.0000 - val_loss: 0.7191 - val_accuracy: 0.8693 - lr: 2.4414e-05
Epoch 100/100
391/391 [==============================] - 33s 85ms/step - loss: 0.1821 - accuracy: 1.0000 - val_loss: 0.7220 - val_accuracy: 0.8680 - lr: 2.4414e-05
[INFO] evaluating network...
precision recall f1-score support
airplane 0.86 0.90 0.88 1000
automobile 0.94 0.94 0.94 1000
bird 0.83 0.80 0.81 1000
cat 0.74 0.74 0.74 1000
deer 0.84 0.84 0.84 1000
dog 0.83 0.79 0.81 1000
frog 0.88 0.91 0.89 1000
horse 0.93 0.90 0.91 1000
ship 0.91 0.94 0.92 1000
truck 0.92 0.92 0.92 1000
accuracy 0.87 10000
macro avg 0.87 0.87 0.87 10000
weighted avg 0.87 0.87 0.87 10000
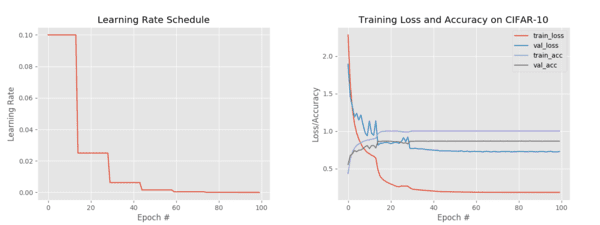
Figure 5 (left) visualizes our learning rate schedule. Notice how after every 15 epochs our learning rate drops, creating the “stair-step”-like effect.
Figure 5 (right) demonstrates the classic signs of step-based learning rate scheduling — you can clearly see our:
- Training/validation loss decrease
- Training/validation accuracy increase
…when our learning rate is dropped.
This is especially pronounced in the first two drops (epochs 15 and 30), after which the drops become less substantial.
This type of steep drop is a classic sign of a step-based learning rate schedule being utilized — if you see that type of training behavior in a paper, publication, or another tutorial, you can be almost sure that they used step-based decay!
Getting back to our accuracy, we’re now at 87% accuracy, an improvement from our first experiment.
Experiment #4: Linear learning rate schedule results
Let’s try using a linear learning rate schedule with Keras by setting power=1.0 :
$ python train.py --schedule linear --lr-plot output/lr_linear_schedule.png --train-plot output/train_linear_schedule.png
[INFO] using 'linear' learning rate decay...
[INFO] loading CIFAR-10 data...
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.1397 - accuracy: 0.4394 - val_loss: 2.5532 - val_accuracy: 0.4208 - lr: 0.1000
Epoch 2/100
391/391 [==============================] - 34s 86ms/step - loss: 1.5470 - accuracy: 0.6350 - val_loss: 1.4195 - val_accuracy: 0.6732 - lr: 0.0990
Epoch 3/100
391/391 [==============================] - 33s 85ms/step - loss: 1.2511 - accuracy: 0.7252 - val_loss: 1.2352 - val_accuracy: 0.7238 - lr: 0.0980
...
Epoch 98/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1047 - accuracy: 1.0000 - val_loss: 0.6106 - val_accuracy: 0.8719 - lr: 0.0030
Epoch 99/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1043 - accuracy: 1.0000 - val_loss: 0.6091 - val_accuracy: 0.8718 - lr: 0.0020
Epoch 100/100
391/391 [==============================] - 33s 86ms/step - loss: 0.1040 - accuracy: 1.0000 - val_loss: 0.6094 - val_accuracy: 0.8724 - lr: 0.0010
[INFO] evaluating network...
precision recall f1-score support
airplane 0.87 0.89 0.88 1000
automobile 0.93 0.95 0.94 1000
bird 0.83 0.81 0.82 1000
cat 0.74 0.75 0.75 1000
deer 0.88 0.84 0.86 1000
dog 0.82 0.79 0.80 1000
frog 0.90 0.93 0.91 1000
horse 0.92 0.91 0.91 1000
ship 0.93 0.94 0.93 1000
truck 0.92 0.92 0.92 1000
accuracy 0.87 10000
macro avg 0.87 0.87 0.87 10000
weighted avg 0.87 0.87 0.87 10000
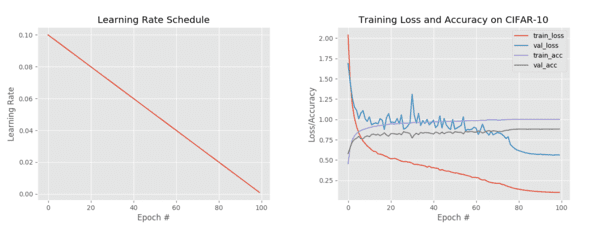
Figure 6 (left) shows that our learning rate is decreasing linearly over time while Figure 6 (right) visualizes our training history.
We’re now seeing a sharper drop in both training and validation loss, especially past approximately epoch 75; however, note that our training loss is dropping significantly faster than our validation loss — we may be at risk of overfitting.
Regardless, we are now obtaining 87% accuracy on our data, similar to Experiment #3 (step-based).
Experiment #5: Polynomial learning rate schedule results
As a final experiment let’s apply polynomial learning rate scheduling with Keras by setting power=5 :
$ python train.py --schedule poly --lr-plot output/lr_poly_schedule.png --train-plot output/train_poly_schedule.png
[INFO] using 'polynomial' learning rate decay...
[INFO] loading CIFAR-10 data...
Epoch 1/100
391/391 [==============================] - 35s 89ms/step - loss: 2.1474 - accuracy: 0.4376 - val_loss: 2.0406 - val_accuracy: 0.4850 - lr: 0.1000
Epoch 2/100
391/391 [==============================] - 34s 86ms/step - loss: 1.5195 - accuracy: 0.6429 - val_loss: 1.5406 - val_accuracy: 0.6380 - lr: 0.0951
Epoch 3/100
391/391 [==============================] - 34s 86ms/step - loss: 1.2210 - accuracy: 0.7337 - val_loss: 1.3527 - val_accuracy: 0.6878 - lr: 0.0904
...
Epoch 98/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1548 - accuracy: 1.0000 - val_loss: 0.6880 - val_accuracy: 0.8627 - lr: 2.4300e-09
Epoch 99/100
391/391 [==============================] - 34s 86ms/step - loss: 0.1548 - accuracy: 1.0000 - val_loss: 0.6824 - val_accuracy: 0.8636 - lr: 3.2000e-10
Epoch 100/100
391/391 [==============================] - 33s 85ms/step - loss: 0.1549 - accuracy: 1.0000 - val_loss: 0.6883 - val_accuracy: 0.8651 - lr: 1.0000e-11
[INFO] evaluating network...
precision recall f1-score support
airplane 0.86 0.90 0.88 1000
automobile 0.93 0.94 0.93 1000
bird 0.84 0.78 0.81 1000
cat 0.75 0.72 0.73 1000
deer 0.87 0.85 0.86 1000
dog 0.78 0.82 0.80 1000
frog 0.87 0.90 0.88 1000
horse 0.91 0.89 0.90 1000
ship 0.93 0.94 0.93 1000
truck 0.91 0.92 0.91 1000
accuracy 0.87 10000
macro avg 0.86 0.87 0.86 10000
weighted avg 0.86 0.87 0.86 10000
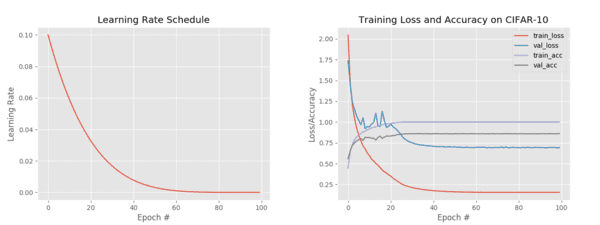
Figure 7 (left) visualizes the fact that our learning rate is now decaying according to our polynomial function while Figure 7 (right) plots our training history.
This time we obtain ~86-87% accuracy.
Commentary on learning rate schedule experiments
Our best experiment was from our fourth experiment where we utilized a linear learning rate schedule.
But does that mean we should always use a linear learning rate schedule?
No, far from it, actually.
The key takeaway here is that for this:
- Particular dataset (CIFAR-10)
- Particular neural network architecture (ResNet)
- Initial learning rate of 1e-2
- Number of training epochs (100)
…is that linear learning rate scheduling worked the best.
No two deep learning projects are alike so you will need to run your own set of experiments, including varying the initial learning rate and the total number of epochs, to determine the appropriate learning rate schedule (additional commentary is included in the “Summary” section of this tutorial as well).
Do other learning rate schedules exist?
Other learning rate schedules exist, and in fact, any mathematical function that can accept an epoch or batch number as an input and returns a learning rate can be considered a “learning rate schedule”. Two other learning rate schedules you may encounter include (1) exponential learning rate decay, as well as (2) cyclical learning rates.
I don’t often use exponential decay as I find that linear and polynomial decay are more than sufficient, but you are more than welcome to subclass the LearningRateDecay class and implement exponential decay if you so wish.
Cyclical learning rates, on the other hand, are very powerful — we’ll be covering cyclical learning rates in a tutorial later in this series.
How do I choose my initial learning rate?
You’ll notice that in this tutorial we did not vary our learning rate, we kept it constant at 1e-2 .
When performing your own experiments you’ll want to combine:
- Learning rate schedules…
- …with different learning rates
Don’t be afraid to mix and match!
The four most important hyperparameters you’ll want to explore, include:
- Initial learning rate
- Number of training epochs
- Learning rate schedule
- Regularization strength/amount (L2, dropout, etc.)
Finding an appropriate balance of each can be challenging, but through many experiments, you’ll be able to find a recipe that leads to a highly accurate neural network.
If you’d like to learn more about my tips, suggestions, and best practices for learning rates, learning rate schedules, and training your own neural networks, refer to my book, Deep Learning for Computer Vision with Python.
What's next? I recommend PyImageSearch University.
30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to utilize Keras for learning rate decay and learning rate scheduling.
Specifically, you discovered how to implement and utilize a number of learning rate schedules with Keras, including:
- The decay schedule built into most Keras optimizers
- Step-based learning rate schedules
- Linear learning rate decay
- Polynomial learning rate schedules
After implementing our learning rate schedules we evaluated each on a set of experiments on the CIFAR-10 dataset.
Our results demonstrated that for an initial learning rate of 1e-2 , the linear learning rate schedule, decaying over 100 epochs, performed the best.
However, this does not mean that a linear learning rate schedule will always outperform other types of schedules. Instead, all this means is that for this:
- Particular dataset (CIFAR-10)
- Particular neural network architecture (ResNet)
- Initial learning rate of
1e-2 - Number of training epochs (
100)
…that linear learning rate scheduling worked the best.
No two deep learning projects are alike so you will need to run your own set of experiments, including varying the initial learning rate, to determine the appropriate learning rate schedule.
I suggest you keep an experiment log that details any hyperparameter choices and associated results, that way you can refer back to it and double-down on experiments that look promising.
Do not expect that you’ll be able to train a neural network and be “one and done” — that rarely, if ever, happens. Instead, set the expectation with yourself that you’ll be running many experiments and tuning hyperparameters as you go along. Machine learning, deep learning, and artificial intelligence as a whole are iterative — you build on your previous results.
Later in this series of tutorials I’ll also be showing you how to select your initial learning rate.
To download the source code to this post, and be notified when future tutorials are published here on PyImageSearch, just enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

