In this tutorial, you will learn how to use Cyclical Learning Rates (CLR) and Keras to train your own neural networks. Using Cyclical Learning Rates you can dramatically reduce the number of experiments required to tune and find an optimal learning rate for your model.
Today is part two in our three-part series on tuning learning rates for deep neural networks:
- Part #1: Keras learning rate schedules and decay (last week’s post)
- Part #2: Cyclical Learning Rates with Keras and Deep Learning (today’s post)
- Part #3: Automatically finding optimal learning rates (next week’s post)
Last week we discussed the concept of learning rate schedules and how we can decay and decrease our learning rate over time according to a set function (i.e., linear, polynomial, or step decrease).
However, there are two problems with basic learning rate schedules:
- We don’t know what the optimal initial learning rate is.
- Monotonically decreasing our learning rate may lead to our network getting “stuck” in plateaus of the loss landscape.
Cyclical Learning Rates take a different approach. Using CLRs, we now:
- Define a minimum learning rate
- Define a maximum learning rate
- Allow the learning rate to cyclically oscillate between the two bounds
In practice, using Cyclical Learning Rates leads to faster convergence and with fewer experiments/hyperparameter updates.
And when we combine CLRs with next week’s technique on automatically finding optimal learning rates, you may never need to tune your learning rates again! (or at least run far fewer experiments to tune them).
To learn how to use Cyclical Learning Rates with Keras, just keep reading!
Cyclical Learning Rates with Keras and Deep Learning
2020-06-11 Update: This blog post is now TensorFlow 2+ compatible!
In the first part of this tutorial, we’ll discuss Cyclical Learning Rates, including:
- What are Cyclical Learning Rates?
- Why should we use Cyclical Learning Rates?
- How do we use Cyclical Learning Rates with Keras?
From there, we’ll implement CLRs and train a variation of GoogLeNet on the CIFAR-10 dataset — I’ll even point out how to use Cyclical Learning Rates with your own custom datasets.
Finally, we’ll review the results of our experiments and you’ll see firsthand how CLRs can reduce the number of learning rate trials you need to perform to find an optimal learning rate range.
What are cyclical learning rates?
As we discussed in last week’s post, we can define learning rate schedules that monotonically decrease our learning rate after each epoch.
By decreasing our learning rate over time we can allow our model to (ideally) descend into lower areas of the loss landscape.
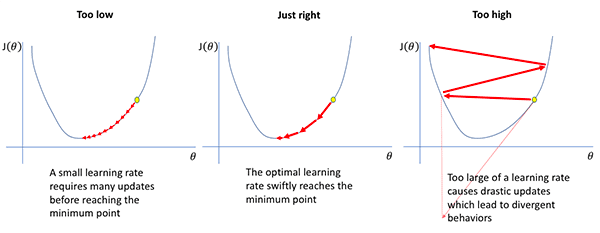
In practice; however, there are a few problems with a monotonically decreasing learning rate:
- First, our model and optimizer are still sensitive to our initial choice in learning rate.
- Second, we don’t know what the initial learning rate should be — we may need to perform 10s to 100s of experiments just to find our initial learning rate.
- Finally, there is no guarantee that our model will descend into areas of low loss when lowering the learning rate.
To address these issues, Leslie Smith of the NRL introduced Cyclical Learning Rates in his 2015 paper, Cyclical Learning Rates for Training Neural Networks.
Now, instead of monotonically decreasing our learning rate, we instead:
- Define the lower bound on our learning rate (called “base_lr”).
- Define the upper bound on the learning rate (called the “max_lr”).
- Allow the learning rate to oscillate back and forth between these two bounds when training, slowly increasing and decreasing the learning rate after every batch update.
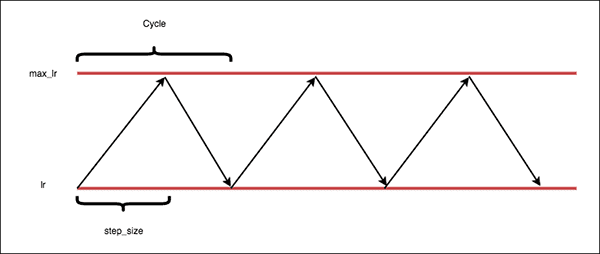
An example of a Cyclical Learning Rate can be seen in Figure 1.
Notice how our learning rate follows a triangular pattern. First, the learning rate is very small. Then, over time, the learning rate continues to grow until it hits the maximum value. The learning rate then descends back down to the base value. This cyclical pattern continues throughout training.
Why should we use Cyclical Learning Rates?
As mentioned above, Cyclical Learning Rates enables our learning rate to oscillate back and forth between a lower and upper bound.
So, why bother going through all the trouble?
Why not just monotonically decrease our learning rate, just as we’ve always done?
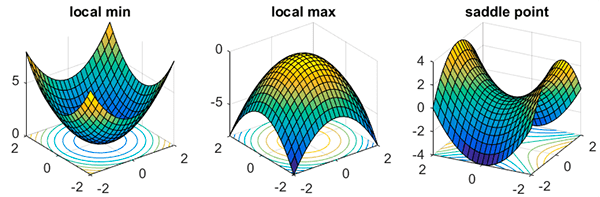
The first reason is that our network may become stuck in either saddle points or local minima, and the low learning rate may not be sufficient to break out of the area and descend into areas of the loss landscape with lower loss.
Secondly, our model and optimizer may be very sensitive to our initial learning rate choice. If we make a poor initial choice in learning rate, our model may be stuck from the very start.
Instead, we can use Cyclical Learning Rates to oscillate our learning rate between upper and lower bounds, enabling us to:
- Have more freedom in our initial learning rate choices.
- Break out of saddle points and local minima.
In practice, using CLRs leads to far fewer learning rate tuning experiments along with near identical accuracy to exhaustive hyperparameter tuning.
How do we use Cyclical Learning Rates?
We’ll be using Brad Kenstler’s implementation of Cyclical Learning Rates for Keras.
In order to use this implementation we need to define a few values first:
- Batch size: Number of training examples to use in a single forward and backward pass of the network during training.
- Batch/Iteration: Number of weight updates per epoch (i.e., # of total training examples divided by the batch size).
- Cycle: Number of iterations it takes for our learning rate to go from the lower bound, ascend to the upper bound, and then descend back to the lower bound again.
- Step size: Number of iterations in a half cycle. Leslie Smith, the creator of CLRs, recommends that the step_size should be
(2-8) * training_iterations_in_epoch). In practice, I have found that step sizes of either 4 or 8 work well in most situations.
With these terms defined, let’s see how they work together to define a Cyclical Learning Rate policy.
The “triangular” policy
The “triangular” Cyclical Learning Rate policy is a simple triangular cycle.
Our learning rate starts off at the base value and then starts to increase.
We reach the maximum learning rate value halfway through the cycle (i.e., the step size, or number of iterations in a half cycle). Once the maximum learning rate is hit, we then decrease the learning rate back to the base value. Again, it takes a half cycle to return to the base learning rate.
This entire process repeats (i.e., cyclical) until training is terminated.
The “triangular2” policy
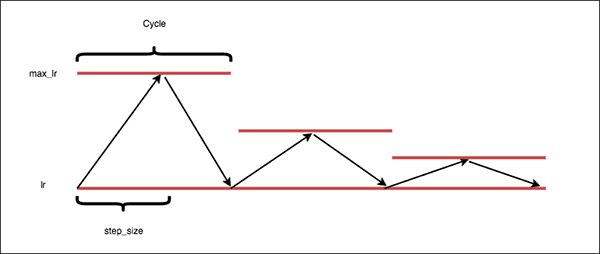
The “triangular2” CLR policy is similar to the standard “triangular” policy, but instead cuts our max learning rate bound in half after every cycle.
The argument here is that we get the best of both worlds:
We can oscillate our learning rate to break out of saddle points/local minima…
…and at the same time decrease our learning rate, enabling us to descend into lower loss areas of the loss landscape.
Furthermore, reducing our maximum learning rate over time helps stabilize our training. Later epochs with the “triangular” policy may exhibit large jumps in both loss and accuracy — the “triangular2” policy will help stabilize these jumps.
The “exp_range” policy
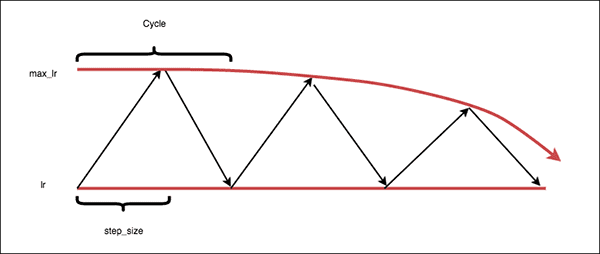
The “exp_range” Cyclical Learning Rate policy is similar to the “triangular2” policy, but, as the name suggests, instead follows an exponential decay, giving you more fine-tuned control in the rate of decline in max learning rate.
Note: In practice, I don’t use the “exp_range” policy — the “triangular” and “triangular2” policies are more than sufficient in the vast majority of projects.
How do I install Cyclical Learning Rates on my system?
The Cyclical Learning Rate implementation we are using is not pip-installable.
Instead, you can either:
- Use the “Downloads” section to grab the file and associated code/data for this tutorial.
- Download the
clr_callback.pyfile from the GitHub repo (linked to above) and insert it into your project.
From there, let’s move on to training our first CNN using a Cyclical Learning Rate.
Configuring your development environment
To configure your system for this tutorial, I first recommend following either of these tutorials:
Either tutorial will help you configure you system with all the necessary software for this blog post in a convenient Python virtual environment.
Please note that PyImageSearch does not recommend or support Windows for CV/DL projects.
Project structure
Go ahead and run the tree command from within the keras-cyclical-learning-rates/ directory to print our project structure:
$ tree --dirsfirst . ├── output │ ├── triangular2_clr_plot.png │ ├── triangular2_training_plot.png │ ├── triangular_clr_plot.png │ └── triangular_training_plot.png ├── pyimagesearch │ ├── __init__.py │ ├── clr_callback.py │ ├── config.py │ └── minigooglenet.py └── train_cifar10.py 2 directories, 9 files
The output/ directory will contain our CLR and accuracy/loss plots.
The pyimagesearch module contains our cyclical learning rate callback class, MiniGoogLeNet CNN, and configuration file:
- The
clr_callback.pyfile contains the Cyclical Learning Rate callback which will update our learning rate automatically at the end of each batch update. - The
minigooglenet.pyfile holds theMiniGoogLeNetCNN which we will train using CIFAR-10 data. We will not review MiniGoogLeNet today — please refer to Deep Learning for Computer Vision with Python to learn more about this CNN architecture. - Our
config.pyis simply a Python file containing configuration variables — we’ll review it in the next section.
Our training script, train_cifar10.py , trains MiniGoogLeNet using the CIFAR-10 dataset. The training script takes advantage of our CLR callback and configuration.
Our configuration file
Before we implement our training script, let’s first review our configuration file:
# import the necessary packages import os # initialize the list of class label names CLASSES = ["airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse", "ship", "truck"]
We will use the os module in our config so that we can construct operating system-agnostic paths directly (Line 2).
From there, our CIFAR-10 CLASSES are defined (Lines 5 and 6).
Let’s define our cyclical learning rate parameters:
# define the minimum learning rate, maximum learning rate, batch size, # step size, CLR method, and number of epochs MIN_LR = 1e-7 MAX_LR = 1e-2 BATCH_SIZE = 64 STEP_SIZE = 8 CLR_METHOD = "triangular" NUM_EPOCHS = 96
The MIN_LR and MAX_LR define our base learning rate and maximum learning rate, respectively (Lines 10 and 11). I know these learning rates will work well when training MiniGoogLeNet per the experiments I have already run for Deep Learning for Computer Vision with Python — next week I will show you how to automatically find these values.
The BATCH_SIZE (Line 12) is the number of training examples per batch update.
We then have the STEP_SIZE which is the number of batch updates in a half cycle (Line 13).
The CLR_METHOD controls our Cyclical Learning Rate policy (Line 14). Here we are using the ”triangular” policy, as discussed in the previous section.
We can calculate the number of full CLR cycles in a given number of epochs via:
NUM_CLR_CYCLES = NUM_EPOCHS / STEP_SIZE / 2
For example, with NUM_EPOCHS = 96 and STEP_SIZE = 8, there will be a total of 6 full cycles: 96 / 8 / 2 = 6.
Finally, we define our output plot paths/filenames:
# define the path to the output training history plot and cyclical # learning rate plot TRAINING_PLOT_PATH = os.path.sep.join(["output", "training_plot.png"]) CLR_PLOT_PATH = os.path.sep.join(["output", "clr_plot.png"])
We’ll plot a training history accuracy/loss plot as well as a cyclical learning rate plot. You may specify the paths + filenames of the plots on Lines 19 and 20.
Implementing our Cyclical Learning Rate training script
With our configuration defined, we can move on to implementing our training script.
Open up train_cifar10.py and insert the following code:
# set the matplotlib backend so figures can be saved in the background
import matplotlib
matplotlib.use("Agg")
# import the necessary packages
from pyimagesearch.minigooglenet import MiniGoogLeNet
from pyimagesearch.clr_callback import CyclicLR
from pyimagesearch import config
from sklearn.preprocessing import LabelBinarizer
from sklearn.metrics import classification_report
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
import numpy as np
Lines 2-15 import our necessary packages. Most notably our CyclicLR (from the clr_callback file) is imported via Line 7. The matplotlib backend is set on Line 3 so that our plots can be written to disk at the end of the training process.
Next, let’s load our CIFAR-10 data:
# load the training and testing data, converting the images from
# integers to floats
print("[INFO] loading CIFAR-10 data...")
((trainX, trainY), (testX, testY)) = cifar10.load_data()
trainX = trainX.astype("float")
testX = testX.astype("float")
# apply mean subtraction to the data
mean = np.mean(trainX, axis=0)
trainX -= mean
testX -= mean
# convert the labels from integers to vectors
lb = LabelBinarizer()
trainY = lb.fit_transform(trainY)
testY = lb.transform(testY)
# construct the image generator for data augmentation
aug = ImageDataGenerator(width_shift_range=0.1,
height_shift_range=0.1, horizontal_flip=True,
fill_mode="nearest")
Lines 20-22 load the CIFAR-10 image dataset. The data is pre-split into training and testing sets.
From there, we calculate the mean and apply mean subtraction (Lines 25-27). Mean subtraction is a normalization/scaling technique that results in improved model accuracy. For more details, please refer to the Practitioner Bundle of Deep Learning for Computer Vision with Python.
Labels are then binarized (Lines 30-32).
Next, we initialize our data augmentation object (Lines 35-37). Data augmentation increases model generalization by producing randomly mutated images from your dataset during training. I’ve written about data augmentation in-depth in Deep Learning for Computer Vision with Python as well as two blog posts (How to use Keras fit and fit_generator (a hands-on tutorial) and Keras ImageDataGenerator and Data Augmentation).
Let’s initialize (1) our model, and (2) our cyclical learning rate callback:
# initialize the optimizer and model
print("[INFO] compiling model...")
opt = SGD(lr=config.MIN_LR, momentum=0.9)
model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10)
model.compile(loss="categorical_crossentropy", optimizer=opt,
metrics=["accuracy"])
# initialize the cyclical learning rate callback
print("[INFO] using '{}' method".format(config.CLR_METHOD))
clr = CyclicLR(
mode=config.CLR_METHOD,
base_lr=config.MIN_LR,
max_lr=config.MAX_LR,
step_size= config.STEP_SIZE * (trainX.shape[0] // config.BATCH_SIZE))
Our model is initialized with stochastic gradient descent (SGD ) optimization and "categorical_crossentropy" loss (Lines 41-44). If you have only two classes in your dataset, be sure to set loss="binary_crossentropy" .
Next, we initialize the cyclical learning rate callback via Lines 48-52. The CLR parameters are provided to the constructor. Now is a great time to review them at the top of the “How do we use Cyclical Learning Rates?” section above. The step_size follow’s Leslie Smith’s recommendation of setting it to be a multiple of the number of batch updates per epoch.
Let’s train and evaluate our model using CLR now:
# train the network
print("[INFO] training network...")
H = model.fit(
x=aug.flow(trainX, trainY, batch_size=config.BATCH_SIZE),
validation_data=(testX, testY),
steps_per_epoch=trainX.shape[0] // config.BATCH_SIZE,
epochs=config.NUM_EPOCHS,
callbacks=[clr],
verbose=1)
# evaluate the network and show a classification report
print("[INFO] evaluating network...")
predictions = model.predict(x=testX, batch_size=config.BATCH_SIZE)
print(classification_report(testY.argmax(axis=1),
predictions.argmax(axis=1), target_names=config.CLASSES))
2020-06-11 Update: Formerly, TensorFlow/Keras required use of a method called .fit_generator in order to accomplish data augmentation. Now, the .fit method can handle data augmentation as well, making for more-consistent code. This also applies to the migration from .predict_generator to .predict. Be sure to check out my articles about fit and fit_generator as well as data augmentation.
Lines 56-62 launch training using the clr callback and data augmentation.
Then Lines 66-68 evaluate the network on the testing set and print a classification_report .
Finally, we’ll generate two plots:
# plot the training loss and accuracy
N = np.arange(0, config.NUM_EPOCHS)
plt.style.use("ggplot")
plt.figure()
plt.plot(N, H.history["loss"], label="train_loss")
plt.plot(N, H.history["val_loss"], label="val_loss")
plt.plot(N, H.history["accuracy"], label="train_acc")
plt.plot(N, H.history["val_accuracy"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend(loc="lower left")
plt.savefig(config.TRAINING_PLOT_PATH)
# plot the learning rate history
N = np.arange(0, len(clr.history["lr"]))
plt.figure()
plt.plot(N, clr.history["lr"])
plt.title("Cyclical Learning Rate (CLR)")
plt.xlabel("Training Iterations")
plt.ylabel("Learning Rate")
plt.savefig(config.CLR_PLOT_PATH)
2020-06-11 Update: In order for this plotting snippet to be TensorFlow 2+ compatible the H.history dictionary keys are updated to fully spell out “accuracy” sans “acc” (i.e., H.history["val_accuracy"] and H.history["accuracy"]). It is semi-confusing that “val” is not spelled out as “validation”; we have to learn to love and live with the API and always remember that it is a work in progress that many developers around the world contribute to.
Two plots are generated:
- Training accuracy/loss history (Lines 71-82). The standard plot format included in most of my tutorials and every experiment of my deep learning book.
- Learning rate history (Lines 86-91). This plot will help us to visually verify that our learning rate is oscillating according to our intentions.
Training with cyclical learning rates
We are now ready to train our CNN using Cyclical Learning Rates with Keras!
Make sure you’ve used the “Downloads” section of this post to download the source code — from there, open up a terminal and execute the following command:
$ python train_cifar10.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] using 'triangular' method
[INFO] training network...
Epoch 1/96
781/781 [==============================] - 21s 27ms/step - loss: 1.9768 - accuracy: 0.2762 - val_loss: 1.6559 - val_accuracy: 0.4040
Epoch 2/96
781/781 [==============================] - 20s 26ms/step - loss: 1.4149 - accuracy: 0.4827 - val_loss: 1.5753 - val_accuracy: 0.4895
Epoch 3/96
781/781 [==============================] - 20s 26ms/step - loss: 1.1499 - accuracy: 0.5902 - val_loss: 1.6790 - val_accuracy: 0.5242
Epoch 4/96
781/781 [==============================] - 20s 26ms/step - loss: 0.9762 - accuracy: 0.6563 - val_loss: 1.1674 - val_accuracy: 0.6079
Epoch 5/96
781/781 [==============================] - 20s 26ms/step - loss: 0.8552 - accuracy: 0.7057 - val_loss: 1.1270 - val_accuracy: 0.6545
...
Epoch 92/96
781/781 [==============================] - 20s 25ms/step - loss: 0.0625 - accuracy: 0.9790 - val_loss: 0.4958 - val_accuracy: 0.8852
Epoch 93/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0472 - accuracy: 0.9842 - val_loss: 0.3810 - val_accuracy: 0.9059
Epoch 94/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0377 - accuracy: 0.9882 - val_loss: 0.3733 - val_accuracy: 0.9092
Epoch 95/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0323 - accuracy: 0.9901 - val_loss: 0.3609 - val_accuracy: 0.9124
Epoch 96/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0277 - accuracy: 0.9919 - val_loss: 0.3516 - val_accuracy: 0.9146
[INFO] evaluating network...
precision recall f1-score support
airplane 0.91 0.94 0.92 1000
automobile 0.95 0.96 0.96 1000
bird 0.89 0.89 0.89 1000
cat 0.83 0.82 0.83 1000
deer 0.91 0.91 0.91 1000
dog 0.88 0.85 0.86 1000
frog 0.92 0.95 0.93 1000
horse 0.95 0.93 0.94 1000
ship 0.96 0.95 0.95 1000
truck 0.95 0.95 0.95 1000
accuracy 0.91 10000
macro avg 0.91 0.91 0.91 10000
weighted avg 0.91 0.91 0.91 10000
As you can see, by using the “triangular” CLR policy we are obtaining 91% accuracy on our CIFAR-10 testing set.
The following figure shows the learning rate plot, demonstrating how it cyclically starts at our lower learning rate bound, increases to the maximum value at half a cycle, and then decreases again to the lower bound, completing the cycle:
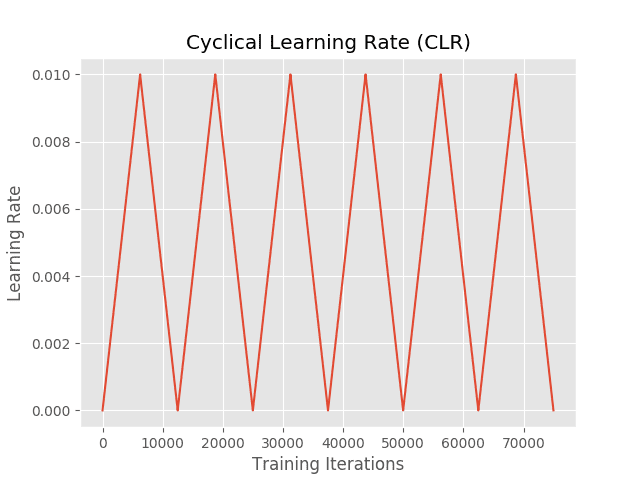
Examining our training history you can see the cyclical behavior of the learning rate:
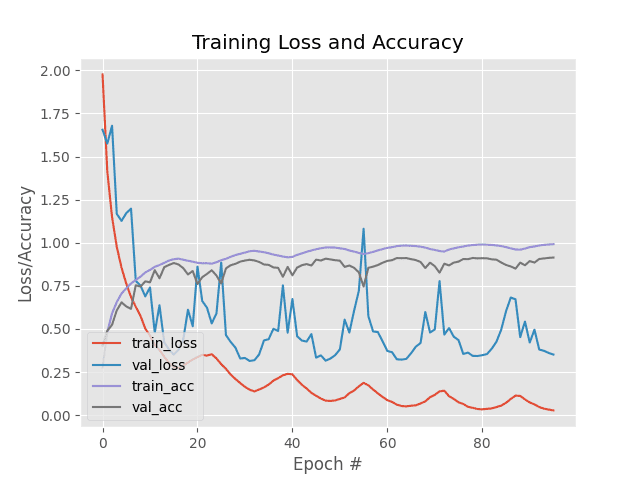
Notice the “wave” in the training accuracy and validation accuracy — the bottom of the wave is our base learning rate, the top of the wave is the upper bound on the learning rate, and the bottom of the wave, just before the next one starts, is the lower learning rate.
Just for fun, go back to Line 14 of the config.py file and update the CLR_METHOD to be ”triangular2” instead of ”triangular”:
# define the minimum learning rate, maximum learning rate, batch size, # step size, CLR method, and number of epochs MIN_LR = 1e-7 MAX_LR = 1e-2 BATCH_SIZE = 64 STEP_SIZE = 8 CLR_METHOD = "triangular2" NUM_EPOCHS = 96
From there, train the network:
$ python train_cifar10.py
[INFO] loading CIFAR-10 data...
[INFO] compiling model...
[INFO] using 'triangular2' method
[INFO] training network...
Epoch 1/96
781/781 [==============================] - 21s 26ms/step - loss: 1.9612 - accuracy: 0.2816 - val_loss: 1.8604 - val_accuracy: 0.3650
Epoch 2/96
781/781 [==============================] - 20s 26ms/step - loss: 1.4167 - accuracy: 0.4832 - val_loss: 1.5907 - val_accuracy: 0.4916
Epoch 3/96
781/781 [==============================] - 21s 26ms/step - loss: 1.1566 - accuracy: 0.5889 - val_loss: 1.2650 - val_accuracy: 0.5667
Epoch 4/96
781/781 [==============================] - 20s 26ms/step - loss: 0.9837 - accuracy: 0.6547 - val_loss: 1.1343 - val_accuracy: 0.6207
Epoch 5/96
781/781 [==============================] - 20s 26ms/step - loss: 0.8690 - accuracy: 0.6940 - val_loss: 1.1572 - val_accuracy: 0.6128
...
Epoch 92/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0711 - accuracy: 0.9765 - val_loss: 0.3636 - val_accuracy: 0.9021
Epoch 93/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0699 - accuracy: 0.9775 - val_loss: 0.3693 - val_accuracy: 0.8995
Epoch 94/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0702 - accuracy: 0.9773 - val_loss: 0.3660 - val_accuracy: 0.9013
Epoch 95/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0682 - accuracy: 0.9782 - val_loss: 0.3644 - val_accuracy: 0.9005
Epoch 96/96
781/781 [==============================] - 20s 26ms/step - loss: 0.0661 - accuracy: 0.9789 - val_loss: 0.3649 - val_accuracy: 0.9007
[INFO] evaluating network...
precision recall f1-score support
airplane 0.90 0.91 0.91 1000
automobile 0.95 0.97 0.96 1000
bird 0.85 0.86 0.86 1000
cat 0.83 0.79 0.81 1000
deer 0.90 0.88 0.89 1000
dog 0.84 0.84 0.84 1000
frog 0.90 0.94 0.92 1000
horse 0.94 0.93 0.93 1000
ship 0.96 0.94 0.95 1000
truck 0.94 0.95 0.94 1000
accuracy 0.90 10000
macro avg 0.90 0.90 0.90 10000
weighted avg 0.90 0.90 0.90 10000
This time we are obtaining 90% accuracy, slightly lower than using the “triangular” policy.
Our learning rate plot visualizes how our learning rate is cyclically updated:
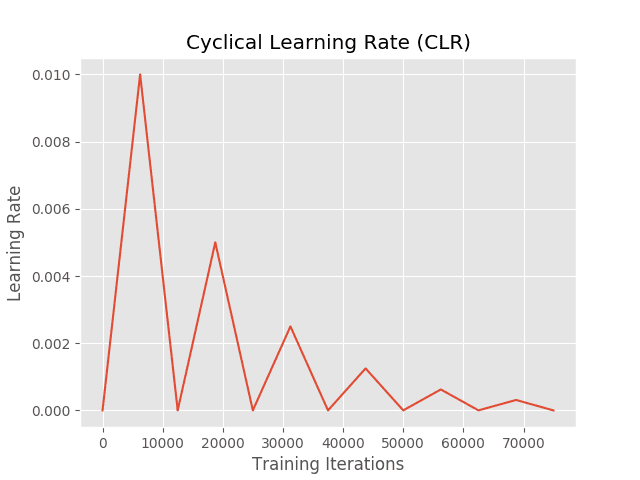
Notice at after each complete cycle the maximum learning rate is halved. Since our maximum learning rate is decreasing after every cycle, our “waves” in the training and validation accuracy will be much less pronounced:
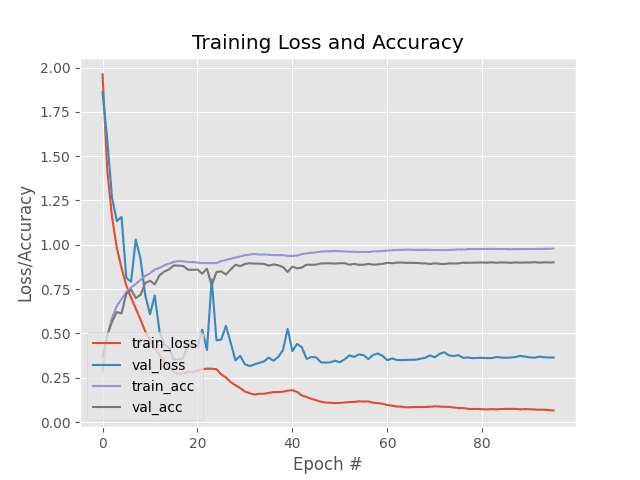
While the “triangular” Cyclical Learning Rate policy obtained slightly better accuracy, it also exhibited far much fluctuation and had more risk of overfitting.
In contrast, the “triangular2” policy, while being less accurate, is more stable in its training.
When performing your own experiments with Cyclical Learning Rates I suggest you test both policies and choose the one that balances both accuracy and stability (i.e., stable training with less risk of overfitting).
In next week’s tutorial, I’ll show you how you can automatically define your minimum and maximum learning rate bounds with Cyclical Learning Rates.
What's next? I recommend PyImageSearch University.

30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to use Cyclical Learning Rates (CLRs) with Keras.
Unlike standard learning rate decay schedules, which monotonically decrease our learning rate, CLRs instead:
- Define a minimum learning rate
- Define a maximum learning rate
- Allow the learning rate to cyclically oscillate between the two bounds
Cyclical Learning rates often lead to faster convergence with fewer experiments and hyperparameter tuning.
But there’s still a problem…
How do we know that the optimal lower and upper bounds of the learning rate are?
That’s a great question — and I’ll be answering it in next week’s post where I’ll show you how to automatically find optimal learning rate values.
I hope you enjoyed today’s post!
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), just enter your email address in the form below.

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

