
In this tutorial, you will learn how to perform face detection with the dlib library using both HOG + Linear SVM and CNNs.

The dlib library is arguably one of the most utilized packages for face recognition. A Python package appropriately named face_recognition wraps dlib’s face recognition functions into a simple, easy to use API.
Note: If you are interested in using dlib and the face_recognition libraries for face recognition, refer to this tutorial, where I cover the topic in detail.
However, I’m often surprised to hear that readers do not know that dlib includes two face detection methods built into the library:
- A HOG + Linear SVM face detector that is accurate and computationally efficient.
- A Max-Margin (MMOD) CNN face detector that is both highly accurate and very robust, capable of detecting faces from varying viewing angles, lighting conditions, and occlusion.
Best of all, the MMOD face detector can run on an NVIDIA GPU, making it super fast!
To learn how to use dlib’s HOG + Linear SVM and MMOD face detectors, just keep reading.
Face detection with dlib (HOG and CNN)
In the first part of this tutorial, you’ll discover dlib’s two face detection functions, one for a HOG + Linear SVM face detector and another for the MMOD CNN face detector.
From there, we’ll configure our development environment and review our project directory structure.
We’ll then implement two Python scripts:
hog_face_detection.py: Applies dlib’s HOG + Linear SVM face detector.cnn_face_detection.py: Utilizes dlib’s MMOD CNN face detector.
We’ll then run these face detectors on a set of images and examine the results, noting when to use each face detector in a given situation.
Let’s get started!
Dlib’s face detection methods

The dlib library provides two functions that can be used for face detection:
- HOG + Linear SVM:
dlib.get_frontal_face_detector() - MMOD CNN:
dlib.cnn_face_detection_model_v1(modelPath)
The get_frontal_face_detector function does not accept any parameters. A call to it returns the pre-trained HOG + Linear SVM face detector included in the dlib library.
Dlib’s HOG + Linear SVM face detector is fast and efficient. By nature of how the Histogram of Oriented Gradients (HOG) descriptor works, it is not invariant to changes in rotation and viewing angle.
For more robust face detection, you can use the MMOD CNN face detector, available via the cnn_face_detection_model_v1 function. This method accepts a single parameter, modelPath, which is the path to the pre-trained mmod_human_face_detector.dat file residing on disk.
Note: I’ve included the mmod_human_face_detector.dat file in the “Downloads” section of this guide, so you don’t have to go hunting for it.
In the remainder of this tutorial, you will learn how to use both of these dlib face detection methods.
Configuring your development environment
To follow this guide, you need to have both the OpenCV library and dlib installed on your system.
Luckily, you can install OpenCV and dlib via pip:
$ pip install opencv-contrib-python $ pip install dlib
If you need help configuring your development environment for OpenCV and dlib, I highly recommend that you read the following two tutorials:
Having problems configuring your development environment?
All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux systems?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project structure
Before we can perform face detection with dlib, we first need to review our project directory structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
From there, take a look at the directory structure:
$ tree . --dirsfirst . ├── images │ ├── avengers.jpg │ ├── concert.jpg │ └── family.jpg ├── pyimagesearch │ ├── __init__.py │ └── helpers.py ├── cnn_face_detection.py ├── hog_face_detection.py └── mmod_human_face_detector.dat
We start with two Python scripts to review:
hog_face_detection.py: Applies HOG + Linear SVM face detection using dlib.cnn_face_detection.py: Performs deep learning-based face detection using dlib by loading the trainedmmod_human_face_detector.datmodel from disk.
Our helpers.py file contains a Python function, convert_and_trim_bb, which will help us:
- Convert dlib bounding boxes to OpenCV bounding boxes
- Trim any bounding box coordinates that fall outside the bounds of the input image
The images directory contains three images that we’ll be applying face detection to with dlib. We can compare the HOG + Linear SVM face detection method with the MMOD CNN face detector.
Creating our bounding box converting and clipping function
OpenCV and dlib represent bounding boxes differently:
- In OpenCV, we think of bounding boxes in terms of a 4-tuple of starting x-coordinate, starting y-coordinate, width, and height
- Dlib represents bounding boxes via
rectangleobject with left, top, right, and bottom properties
Furthermore, bounding boxes returned by dlib may fall outside the bounds of the input image dimensions (negative values or values outside the width and height of the image).
To make applying face detection with dlib easier, let’s create a helper function to (1) convert the bounding box coordinates to standard OpenCV ordering and (2) trim any bounding box coordinates that fall outside the image’s range.
Open the helpers.py file inside the pyimagesearch module, and let’s get to work:
def convert_and_trim_bb(image, rect): # extract the starting and ending (x, y)-coordinates of the # bounding box startX = rect.left() startY = rect.top() endX = rect.right() endY = rect.bottom() # ensure the bounding box coordinates fall within the spatial # dimensions of the image startX = max(0, startX) startY = max(0, startY) endX = min(endX, image.shape[1]) endY = min(endY, image.shape[0]) # compute the width and height of the bounding box w = endX - startX h = endY - startY # return our bounding box coordinates return (startX, startY, w, h)
Our convert_and_trim_bb function requires two parameters: the input image we applied face detection to and the rect object returned by dlib.
Lines 4-7 extract the starting and ending (x, y)-coordinates of the bounding box.
We then ensure the bounding box coordinates fall within the width and height of the input image on Lines 11-14.
The final step is to compute the width and height of the bounding box (Lines 17 and 18) and then return a 4-tuple of the bounding box coordinates in startX, startY, w, and h order.
Implementing HOG + Linear SVM face detection with dlib
With our convert_and_trim_bb helper utility implemented, we can move on to perform HOG + Linear SVM face detection using dlib.
Open the hog_face_detection.py file in your project directory structure and insert the following code:
# import the necessary packages from pyimagesearch.helpers import convert_and_trim_bb import argparse import imutils import time import dlib import cv2
Lines 2-7 import our required Python packages. Notice that the convert_and_trim_bb function we just implemented is imported.
While we import cv2 for our OpenCV bindings, we also import dlib, so we can access its face detection functionality.
Next is our command line arguments:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
ap.add_argument("-u", "--upsample", type=int, default=1,
help="# of times to upsample")
args = vars(ap.parse_args())
We have two command line arguments to parse:
--image: The path to the input image where we apply HOG + Linear SVM face detection.--upsample: Number of times to upsample an image before applying face detection.
To detect small faces in a large input image, we may wish to increase the resolution of the input image, thereby making the smaller faces appear larger. Doing so allows our sliding window to detect the face.
The downside to upsampling is that it creates more layers of our image pyramid, making the detection process slower.
For faster face detection, set the --upsample value to 0, meaning that no upsampling is performed (but you risk missing face detections).
Next, let’s load dlib’s HOG + Linear SVM face detector from disk:
# load dlib's HOG + Linear SVM face detector
print("[INFO] loading HOG + Linear SVM face detector...")
detector = dlib.get_frontal_face_detector()
# load the input image from disk, resize it, and convert it from
# BGR to RGB channel ordering (which is what dlib expects)
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# perform face detection using dlib's face detector
start = time.time()
print("[INFO[ performing face detection with dlib...")
rects = detector(rgb, args["upsample"])
end = time.time()
print("[INFO] face detection took {:.4f} seconds".format(end - start))
A call to dlib.get_frontal_face_detector() returns dlib’s HOG + Linear SVM face detector (Line 19).
We then proceed to:
- Load the input
imagefrom disk - Resize the image (the smaller the image is, the faster HOG + Linear SVM will run)
- Convert the image from BGR to RGB channel ordering (dlib expects RGB images)
From there, we apply our HOG + Linear SVM face detector on Line 30, timing how long the face detection process takes.
Let’s now parse our bounding boxes:
# convert the resulting dlib rectangle objects to bounding boxes,
# then ensure the bounding boxes are all within the bounds of the
# input image
boxes = [convert_and_trim_bb(image, r) for r in rects]
# loop over the bounding boxes
for (x, y, w, h) in boxes:
# draw the bounding box on our image
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
Keep in mind that the returned rects list needs some work — we need to parse the dlib rectangle objects into a 4-tuple of starting x-coordinate, starting y-coordinate, width, and height — and that’s exactly what Line 37 accomplishes.
For each rect, we call our convert_and_trim_bb function, ensuring that both (1) all bounding box coordinates fall within the spatial dimensions of the image and (2) our returned bounding boxes are in the proper 4-tuple format.
Dlib HOG + Linear SVM face detection results
Let’s look at the results of applying our dlib HOG + Linear SVM face detector to a set of images.
Be sure to access the “Downloads” section of this tutorial to retrieve the source code, example images, and pre-trained models.
From there, open a terminal window and execute the following command:
$ python hog_face_detection.py --image images/family.jpg [INFO] loading HOG + Linear SVM face detector... [INFO[ performing face detection with dlib... [INFO] face detection took 0.1062 seconds

Figure 3 displays the results of applying dlib’s HOG + Linear SVM face detector to an input image containing multiple faces.
The face detection process took  0.1 seconds, implying that we could process 10 frames per second in a video stream scenario.
0.1 seconds, implying that we could process 10 frames per second in a video stream scenario.
Most importantly, note that each of the four faces was correctly detected.
Let’s try a different image:
$ python hog_face_detection.py --image images/avengers.jpg [INFO] loading HOG + Linear SVM face detector... [INFO[ performing face detection with dlib... [INFO] face detection took 0.1425 seconds

A couple of years ago, back when Avengers: Endgame came out, my wife and I decided to dress up as “dead Avengers” from the movie (sorry if you haven’t seen the movie but come on, it’s been two years already!)
Notice that my wife’s face (errr, Black Widow?) was detected, but apparently, dlib’s HOG + Linear SVM face detector doesn’t know what Iron Man looks like.
In all likelihood, my face wasn’t detected because my head is slightly rotated and is not a “straight-on view” for the camera. Again, the HOG + Linear SVM family of object detectors does not perform well under rotation or viewing angle changes.
Let’s look at one final image, this one more densely packed with faces:
$ python hog_face_detection.py --image images/concert.jpg [INFO] loading HOG + Linear SVM face detector... [INFO[ performing face detection with dlib... [INFO] face detection took 0.1069 seconds
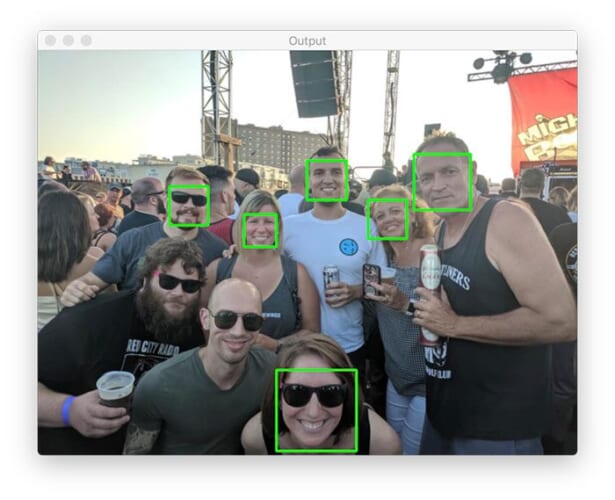
Back before COVID, there were these things called “concerts.” Bands used to get together and play live music for people in exchange for money. Hard to believe, I know.
A bunch of my friends got together for a concert a few years ago. And while there are clearly eight faces in this image, only six of them are detected.
As we’ll see later in this tutorial, we can use dlib’s MMOD CNN face detector to improve face detection accuracy and detect all the faces in this image.
Implementing CNN face detection with dlib
So far, we have learned how to perform face detection with dlib’s HOG + Linear SVM model. This method worked well, but there is far more accuracy to be obtained by using dlib’s MMOD CNN face detector.
Let’s learn how to use dlib’s deep learning face detector now:
# import the necessary packages from pyimagesearch.helpers import convert_and_trim_bb import argparse import imutils import time import dlib import cv2
Our imports here are identical to our previous script on HOG + Linear SVM face detection.
The command line arguments are similar, but with one addition (the --model) argument:
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str, required=True,
help="path to input image")
ap.add_argument("-m", "--model", type=str,
default="mmod_human_face_detector.dat",
help="path to dlib's CNN face detector model")
ap.add_argument("-u", "--upsample", type=int, default=1,
help="# of times to upsample")
args = vars(ap.parse_args())
We have three command line arguments here:
--image: The path to the input image residing on disk.--model: Our pre-trained dlib MMOD CNN face detector.--upsample: The number of times to upsample an image before applying face detection.
With our command line arguments taken care of, we can now load dlib’s deep learning face detector from disk:
# load dlib's CNN face detector
print("[INFO] loading CNN face detector...")
detector = dlib.cnn_face_detection_model_v1(args["model"])
# load the input image from disk, resize it, and convert it from
# BGR to RGB channel ordering (which is what dlib expects)
image = cv2.imread(args["image"])
image = imutils.resize(image, width=600)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# perform face detection using dlib's face detector
start = time.time()
print("[INFO[ performing face detection with dlib...")
results = detector(rgb, args["upsample"])
end = time.time()
print("[INFO] face detection took {:.4f} seconds".format(end - start))
Line 22 loads the detector from disk by calling dlib.cnn_face_detection_model_v1. Here we pass in --model, the path to where the trained dlib face detector resides.
From there, we preprocess our image (Lines 26-28) and then apply the face detector (Line 33).
Just as we parsed the HOG + Linear SVM results, we need to the same here, but one with one caveat:
# convert the resulting dlib rectangle objects to bounding boxes,
# then ensure the bounding boxes are all within the bounds of the
# input image
boxes = [convert_and_trim_bb(image, r.rect) for r in results]
# loop over the bounding boxes
for (x, y, w, h) in boxes:
# draw the bounding box on our image
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
# show the output image
cv2.imshow("Output", image)
cv2.waitKey(0)
Dlib’s HOG + Linear SVM detector returns a list of rectangle objects; however, the MMOD CNN object detector returns a list of result objects, each with its own rectangle (hence we use r.rect in the list comprehension). Otherwise, the implementation is the same.
Finally, we loop over the bounding boxes and draw them on our output image.
Dlib’s CNN face detector results
Let’s see how dlib’s MMOD CNN face detector stacks up to the HOG + Linear SVM face detector.
To follow along, be sure to access the “Downloads” section of this guide to retrieve the source code, example images, and pre-trained dlib face detector.
From there, you can open a terminal and execute the following command:
$ python cnn_face_detection.py --image images/family.jpg [INFO] loading CNN face detector... [INFO[ performing face detection with dlib... [INFO] face detection took 2.3075 seconds
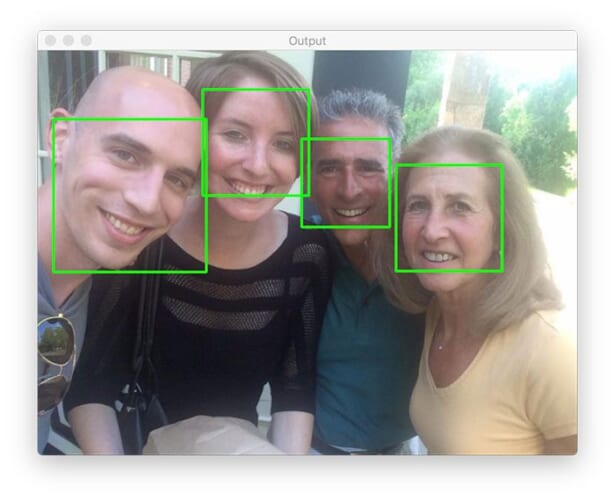
Just like the HOG + Linear SVM implementation, dlib’s MMOD CNN face detector can correctly detect all four faces in the input image.
Let’s try another image:
$ python cnn_face_detection.py --image images/avengers.jpg [INFO] loading CNN face detector... [INFO[ performing face detection with dlib... [INFO] face detection took 3.0468 seconds

Previously, HOG + Linear SVM failed to detect my face on the left. But by using dlib’s deep learning face detector, we can correctly detect both faces.
Let’s look at one final image:
$ python cnn_face_detection.py --image images/concert.jpg [INFO] loading CNN face detector... [INFO[ performing face detection with dlib... [INFO] face detection took 2.2520 seconds

Before, using HOG + Linear SVM, we could only detect six of the eight faces in this image. But as our output shows, swapping over to dlib’s deep learning face detector results in all eight faces being detected.
Which dlib face detector should I use?
If you are using a CPU and speed is not an issue, use dlib’s MMOD CNN face detector. It’s far more accurate and robust than the HOG + Linear SVM face detector.
Additionally, if you have access to a GPU, then there’s no doubt that you should be using the MMOD CNN face detector — you’ll enjoy all the benefits of accurate face detection along with the speed of being able to run in real-time.
Suppose you are limited to just a CPU. In that case, speed is a concern, and you’re willing to tolerate a bit less accuracy, then go with HOG + Linear SVM — it’s still an accurate face detector and significantly more accurate than OpenCV’s Haar cascade face detector.
What's next? I recommend PyImageSearch University.
30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
In this tutorial, you learned how to perform face detection using the dlib library.
Dlib provides two methods to perform face detection:
- HOG + Linear SVM:
dlib.get_frontal_face_detector() - MMOD CNN:
dlib.cnn_face_detection_model_v1(modelPath)
The HOG + Linear SVM face detector will be faster than the MMOD CNN face detector but will also be less accurate as HOG + Linear SVM does not tolerate changes in the viewing angle rotation.
For more robust face detection, use dlib’s MMOD CNN face detector. This model requires significantly more computation (and is thus slower) but is much more accurate and robust to changes in face rotation and viewing angle.
Furthermore, if you have access to a GPU, you can run dlib’s MMOD CNN face detector on it, resulting in real-time face detection speed. The MMOD CNN face detector combined with a GPU is a match made in heaven — you get both the accuracy of a deep neural network along with the speed of a less computationally expensive model.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.