
In this tutorial, you will learn the basics of PyTorch’s Torch Hub.
This lesson is part 1 of a 6-part series on Torch Hub:
- Torch Hub Series #1: Introduction to Torch Hub (this tutorial)
- Torch Hub Series #2: VGG and ResNet
- Torch Hub Series #3: YOLO v5 and SSD — Models on Object Detection
- Torch Hub Series #4: PGAN — Model on GAN
- Torch Hub Series #5: MiDaS — Model on Depth Estimation
- Torch Hub Series #6: Image Segmentation
To learn how to use Torch Hub, just keep reading.
Introduction to Torch Hub
It was 2020 when my friends and I worked night and day to finish our final year project. Like most students in our year, we decided it was a good idea to leave it till the very end.
That wasn’t the brightest idea from our end. What followed were neverending nights of constant model calibration and training, burning through gigabytes of cloud storage, and maintaining records for deep learning model results.
The environment that we had created for ourselves did not only harm our efficiency, but it affected our morale. Due to the sheer individual brilliance of my other teammates, we managed to complete our project.
In retrospect, I realized how much more efficient our work could have been — and so much more enjoyable — had we chosen a better ecosystem to work in.
Fortunately, you don’t have to make the same mistakes I made.
The creators of PyTorch often emphasized that a key intention behind this initiative is to bridge the gap between research and production. PyTorch now stands toe to toe with its contemporaries on many fronts, being utilized equally in both research and production ecosystems.
One of the ways they’ve achieved this is through Torch Hub. Torch Hub as a concept was conceived to further extend PyTorch’s credibility as a production-based framework. In today’s tutorial, we’ll learn how to utilize Torch Hub to store and publish pre-trained models for wide-scale use.
What Is Torch Hub?
In Computer Science, many believe that a key puzzle piece in the bridge between research and production is reproducibility. Building on that very notion, PyTorch introduced Torch Hub, an Application Programmable Interface (API), which allows two programs to interact with each other and enhances the workflow for easy research reproducibility.
Torch Hub lets you publish pre-trained models to help in the cause of research sharing and reproducibility. The process of harnessing Torch Hub is simple, but before moving further, let’s configure the prerequisites of our system!
Configuring Your Development Environment
To follow this guide, you need to have the OpenCV library installed on your system.
Luckily, OpenCV is pip-installable:
$ pip install opencv-contrib-python
If you need help configuring your development environment for OpenCV, I highly recommend that you read our pip install OpenCV guide — it will have you up and running in a matter of minutes.
Having Problems Configuring Your Development Environment?

All that said, are you:
- Short on time?
- Learning on your employer’s administratively locked system?
- Wanting to skip the hassle of fighting with the command line, package managers, and virtual environments?
- Ready to run the code right now on your Windows, macOS, or Linux system?
Then join PyImageSearch University today!
Gain access to Jupyter Notebooks for this tutorial and other PyImageSearch guides that are pre-configured to run on Google Colab’s ecosystem right in your web browser! No installation required.
And best of all, these Jupyter Notebooks will run on Windows, macOS, and Linux!
Project Structure
We first need to review our project structure.
Start by accessing the “Downloads” section of this tutorial to retrieve the source code and example images.
Before moving to the directory, let’s take a look at the project structure in Figure 2.
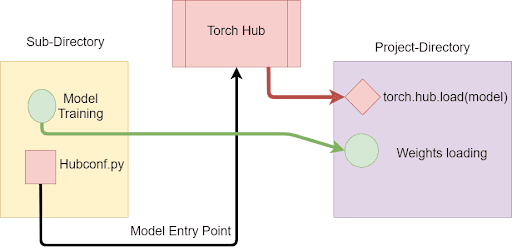
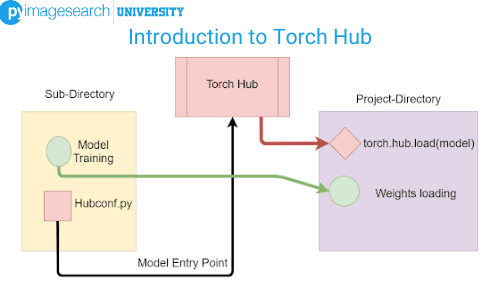
Today, we’ll be working with two directories. This is to help you better understand the use of Torch Hub.
The subdirectory is where we’ll initialize and train our model. Here, we’ll create a hubconf.py script. The hubconf.py script contains callable functions called entry_points. These callable functions initialize and return the models which the user requires. Hence, this script will connect our own created model to Torch Hub.
In our main Project Directory, we’ll be using torch.hub.load to load our model from Torch Hub. After loading the model with pre-trained weights, we’ll evaluate it on some sample data.
A Generalized Outlook on Torch Hub
Torch Hub already hosts an array of models for various tasks, as seen in Figure 3.
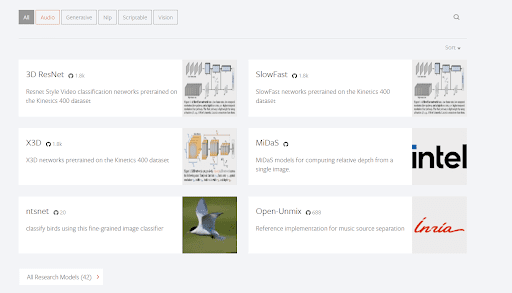
As you can see, there are a total of 42 research models that Torch Hub has accepted in its official showcase. Each model belongs to one or more of the following labels: Audio, Generative, Natural Language Processing (NLP), scriptable, and vision. These models have also been trained on widely accepted benchmark datasets (e.g., Kinetics 400 and COCO 2017).
It’s easy to use these models in your projects using the torch.hub.load function. Let’s look at an example of how it works.
We’ll look at Torch Hub’s official documentation of using a DCGAN trained on fashion-gen to generate some images.
(If you want to know more about DCGANs, do check out this blog.)
# USAGE
# python inference.py
# import the necessary packages
import matplotlib.pyplot as plt
import torchvision
import argparse
import torch
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-n", "--num-images", type=int, default=64,
help="# of images you want the DCGAN to generate")
args = vars(ap.parse_args())
# check if gpu is available for use
useGpu = True if torch.cuda.is_available() else False
# load the DCGAN model
model = torch.hub.load("facebookresearch/pytorch_GAN_zoo:hub", "DCGAN",
pretrained=True, useGPU=useGpu)
On Lines 11-14, we created an argument parser to give the user more freedom to choose the batch size of generated images.
To use the Facebook Research pretrained DCGAN model, we just need the torch.hub.load function as shown on Lines 20 and 21. The torch.hub.load function here takes in the following arguments:
repo_or_dir: The repository name in the formatrepo_owner/repo_name:branch/tag_nameif thesourceargument is set togithub. Otherwise, it will point to the desired path in your local machine.entry_point: To publish a model in torch hub, you need to have a script calledhubconf.pyin your repository/directory. In that script, you’ll define normal callable functions known as entry points. Calling the entry points to return the desired models. You’ll learn more aboutentry_pointlater in this blog.pretrainedanduseGpu: These fall under the*argsor the arguments banner of this function. These arguments are for the callable model.
Now, this isn’t the only major function Torch Hub offers. You can use several other notable functions like torch.hub.list to list all available entry points (callable functions) belonging to the repository, and torch.hub.help to show the documentation docstring of the target entry point.
# generate random noise to input to the generator (noise, _) = model.buildNoiseData(args["num_images"]) # turn off autograd and feed the input noise to the model with torch.no_grad(): generatedImages = model.test(noise) # reconfigure the dimensions of the images to make them channel # last and display the output output = torchvision.utils.make_grid(generatedImages).permute( 1, 2, 0).cpu().numpy() plt.imshow(output) plt.show()
On Line 24, we use a function exclusive to the called model named buildNoiseData to generate random input noise, keeping the input size in mind.
Turning off automatic gradients (Line 27), we generate images by feeding the noise to the model.
Before plotting the images, we do a dimensional re-shaping of the images on Lines 32-35 (since PyTorch works with channel first tensors, we need to make them channel last again). The output will look like Figure 4.

Voila! This is all you need to use a pre-trained state-of-the-art DCGAN model for your purposes. Using the pre-trained models in Torch Hub is THAT easy. However, we are not stopping there, are we?
Calling a pre-trained model to see how the latest state-of-the-art research performs is fine, but what about when we produce state-of-the-art results using our research? For that, we’ll next learn how to publish our own created models on Torch Hub.
Using Torch Hub on Your PyTorch Models
Let’s take a trip down memory lane to July 12, 2021, when Adrian Rosebrock released a blog post that taught you how to build a simple 2-layered neural network on PyTorch. The blog taught you to define your own simple neural networks, and train and test them on user-generated data.
Today, we’ll train our simple neural network and publish it using Torch Hub. I will not go into a full dissection of the code since a tutorial for that already exists. For a detailed and precise dive into building a simple neural network, refer to this blog.
Building a Simple Neural Network
Next, we’ll go through the salient parts of the code. For that, we’ll be moving into the subdirectory. First, let’s build our simple neural network in mlp.py!
# import the necessary packages
from collections import OrderedDict
import torch.nn as nn
# define the model function
def get_training_model(inFeatures=4, hiddenDim=8, nbClasses=3):
# construct a shallow, sequential neural network
mlpModel = nn.Sequential(OrderedDict([
("hidden_layer_1", nn.Linear(inFeatures, hiddenDim)),
("activation_1", nn.ReLU()),
("output_layer", nn.Linear(hiddenDim, nbClasses))
]))
# return the sequential model
return mlpModel
The get_training_model function on Line 6 takes in parameters (input size, hidden layer size, output classes). Inside the function, we use nn.Sequential to create a 2-layered neural network, consisting of a single hidden layer with ReLU activator and an output layer (Lines 8-12).
Training the Neural Network
We won’t be using any external dataset to train the model. Instead, we’ll generate data points ourselves. Let’s hop into train.py.
# import the necessary packages
from pyimagesearch import mlp
from torch.optim import SGD
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
import torch.nn as nn
import torch
import os
# define the path to store your model weights
MODEL_PATH = os.path.join("output", "model_wt.pth")
# data generator function
def next_batch(inputs, targets, batchSize):
# loop over the dataset
for i in range(0, inputs.shape[0], batchSize):
# yield a tuple of the current batched data and labels
yield (inputs[i:i + batchSize], targets[i:i + batchSize])
# specify our batch size, number of epochs, and learning rate
BATCH_SIZE = 64
EPOCHS = 10
LR = 1e-2
# determine the device we will be using for training
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print("[INFO] training using {}...".format(DEVICE))
First, we create a path to save the trained model weights on Line 11, which will be used later. The next_batch function on Lines 14-18 will act as the data generator for our project, yielding batches of data for efficient training.
Next, we set up hyperparameters (Lines 21-23) and set our DEVICE to cuda if a compatible GPU is available (Line 26).
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
On Lines 32 and 33, we use the make_blobs function to mimic data points of an actual three-class dataset. Using scikit-learn’s train_test_split function, we create the training and test splits of the data.
# initialize our model and display its architecture
mlp = mlp.get_training_model().to(DEVICE)
print(mlp)
# initialize optimizer and loss function
opt = SGD(mlp.parameters(), lr=LR)
lossFunc = nn.CrossEntropyLoss()
# create a template to summarize current training progress
trainTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
On Line 45, we call the get_training_model function from the mlp.py module and initialize the model.
We choose stochastic gradient descent as the optimizer (Line 49) and Cross-Entropy loss as the loss function (Line 50).
The trainTemplate variable on Line 53 will act as a string template to print accuracy and loss.
# loop through the epochs
for epoch in range(0, EPOCHS):
# initialize tracker variables and set our model to trainable
print("[INFO] epoch: {}...".format(epoch + 1))
trainLoss = 0
trainAcc = 0
samples = 0
mlp.train()
# loop over the current batch of data
for (batchX, batchY) in next_batch(trainX, trainY, BATCH_SIZE):
# flash data to the current device, run it through our
# model, and calculate loss
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# zero the gradients accumulated from the previous steps,
# perform backpropagation, and update model parameters
opt.zero_grad()
loss.backward()
opt.step()
# update training loss, accuracy, and the number of samples
# visited
trainLoss += loss.item() * batchY.size(0)
trainAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current training batch
trainTemplate = "epoch: {} train loss: {:.3f} train accuracy: {:.3f}"
print(trainTemplate.format(epoch + 1, (trainLoss / samples),
(trainAcc / samples)))
Looping over the training epochs, we initialize the losses (Lines 59-61) and set the model to training mode (Line 62).
Using the next_batch function, we iterate through batches of training data (Line 65). After loading them to the device (Line 68), the predictions for the data batch are obtained on Line 69. These predictions are then fed to the loss function for loss calculation (Line 70).
The gradients are flushed using zero_grad (Line 74), followed by backpropagation on Line 75. Finally, the optimizer parameter is updated on Line 76.
For each epoch, the training loss, accuracy, and sample size variables are upgraded (Lines 80-82) and displayed using the template on Line 85.
# initialize tracker variables for testing, then set our model to
# evaluation mode
testLoss = 0
testAcc = 0
samples = 0
mlp.eval()
# initialize a no-gradient context
with torch.no_grad():
# loop over the current batch of test data
for (batchX, batchY) in next_batch(testX, testY, BATCH_SIZE):
# flash the data to the current device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# run data through our model and calculate loss
predictions = mlp(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
# display model progress on the current test batch
testTemplate = "epoch: {} test loss: {:.3f} test accuracy: {:.3f}"
print(testTemplate.format(epoch + 1, (testLoss / samples),
(testAcc / samples)))
print("")
# save model to the path for later use
torch.save(mlp.state_dict(), MODEL_PATH)
We set the model to eval mode for model evaluation and do the same during the training phase, except for backpropagation.
On Line 121, we have the most important step of saving the model weights for later use.
Let’s assess the epoch-wise performance of our model!
[INFO] training using cpu... [INFO] preparing data... Sequential( (hidden_layer_1): Linear(in_features=4, out_features=8, bias=True) (activation_1): ReLU() (output_layer): Linear(in_features=8, out_features=3, bias=True) ) [INFO] epoch: 1... epoch: 1 train loss: 0.798 train accuracy: 0.649 epoch: 1 test loss: 0.788 test accuracy: 0.613 [INFO] epoch: 2... epoch: 2 train loss: 0.694 train accuracy: 0.665 epoch: 2 test loss: 0.717 test accuracy: 0.613 [INFO] epoch: 3... epoch: 3 train loss: 0.635 train accuracy: 0.669 epoch: 3 test loss: 0.669 test accuracy: 0.613 ... [INFO] epoch: 7... epoch: 7 train loss: 0.468 train accuracy: 0.693 epoch: 7 test loss: 0.457 test accuracy: 0.740 [INFO] epoch: 8... epoch: 8 train loss: 0.385 train accuracy: 0.861 epoch: 8 test loss: 0.341 test accuracy: 0.973 [INFO] epoch: 9... epoch: 9 train loss: 0.286 train accuracy: 0.980 epoch: 9 test loss: 0.237 test accuracy: 0.993 [INFO] epoch: 10... epoch: 10 train loss: 0.211 train accuracy: 0.985 epoch: 10 test loss: 0.173 test accuracy: 0.993
Since we are training on data generated by paradigms we set, our training process went smoothly, reaching a final training accuracy of 0.985.
Configuring the hubconf.py script
With model training complete, our next step is to configure the hubconf.py file in the repo to make our model accessible through Torch Hub.
# import the necessary packages
import torch
from pyimagesearch import mlp
# define entry point/callable function
# to initialize and return model
def custom_model():
""" # This docstring shows up in hub.help()
Initializes the MLP model instance
Loads weights from path and
returns the model
"""
# initialize the model
# load weights from path
# returns model
model = mlp.get_training_model()
model.load_state_dict(torch.load("model_wt.pth"))
return model
As mentioned earlier, we have created an entry point called custom_model on Line 7. Inside the entry_point, we initialize the simple neural network from the mlp.py module (Line 16). Next, we load the weights we previously saved (Line 17). This current setup is made such that this function will look for the model weights in your project directory. You can host the weights on a cloud platform and choose the path accordingly.
Now, we’ll use Torch Hub to access this model and test it on our data.
Using torch.hub.load to Call Our Model
Coming back to our main project directory, let’s hop into the hub_usage.py script.
# USAGE
# python hub_usage.py
# import the necessary packages
from pyimagesearch.data_gen import next_batch
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
import torch.nn as nn
import argparse
import torch
# construct the argument parser and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-b", "--batch-size", type=int, default=64,
help="input batch size")
args = vars(ap.parse_args())
After importing the necessary packages, we create an argument parser (Lines 13-16) for the user to input the batch size for the data.
# load the model using torch hub
print("[INFO] loading the model using torch hub...")
model = torch.hub.load("cr0wley-zz/torch_hub_test:main",
"custom_model")
# generate a 3-class classification problem with 1000 data points,
# where each data point is a 4D feature vector
print("[INFO] preparing data...")
(X, Y) = make_blobs(n_samples=1000, n_features=4, centers=3,
cluster_std=2.5, random_state=95)
# create training and testing splits, and convert them to PyTorch
# tensors
(trainX, testX, trainY, testY) = train_test_split(X, Y,
test_size=0.15, random_state=95)
trainX = torch.from_numpy(trainX).float()
testX = torch.from_numpy(testX).float()
trainY = torch.from_numpy(trainY).float()
testY = torch.from_numpy(testY).float()
On Lines 20 and 21, we use torch.hub.load to initialize our own model, the same way we had loaded the DCGAN model as shown earlier. The model has been initialized and the weights have been loaded according to the entry point in the hubconf.py script in our subdirectory. As you can notice, we give the subdirectory github repository as the parameter.
Now, for evaluation of the model, we’ll create data the same way we had created during our model training (Lines 26 and 27) and use train_test_split to create data splits (Lines 31-36).
# initialize the neural network loss function
lossFunc = nn.CrossEntropyLoss()
# set device to cuda if available and initialize
# testing loss and accuracy
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
testLoss = 0
testAcc = 0
samples = 0
# set model to eval and grab a batch of data
print("[INFO] setting the model in evaluation mode...")
model.eval()
(batchX, batchY) = next(next_batch(testX, testY, args["batch_size"]))
On Line 39, we initialize the cross-entropy loss function as done during the model training. We proceed to initialize the evaluation metrics on Lines 44-46.
The model is set to evaluation mode (Line 50), and a single batch of data is grabbed to be evaluated upon by the model (Line 51).
# initialize a no-gradient context
with torch.no_grad():
# load the data into device
(batchX, batchY) = (batchX.to(DEVICE), batchY.to(DEVICE))
# pass the data through the model to get the output and calculate
# loss
predictions = model(batchX)
loss = lossFunc(predictions, batchY.long())
# update test loss, accuracy, and the number of
# samples visited
testLoss += loss.item() * batchY.size(0)
testAcc += (predictions.max(1)[1] == batchY).sum().item()
samples += batchY.size(0)
print("[INFO] test loss: {:.3f}".format(testLoss / samples))
print("[INFO] test accuracy: {:.3f}".format(testAcc / samples))
Turning off the automatic gradients (Line 54), we load the batch of data to the device and feed it to the model (Lines 56-60). The lossFunc proceeds to calculate the loss on Line 61.
With the help of the loss, we update the accuracy variable on Line 66, along with some other metrics like sample size (Line 67).
Let’s see how the model fared!
[INFO] loading the model using torch hub... [INFO] preparing data... [INFO] setting the model in evaluation mode... Using cache found in /root/.cache/torch/hub/cr0wley-zz_torch_hub_test_main [INFO] test loss: 0.086 [INFO] test accuracy: 0.969
Since we created our test data using the same paradigms used during training the model, it performed as expected, with a test accuracy of 0.969.
What's next? I recommend PyImageSearch University.
30+ total classes • 39h 44m video • Last updated: 12/2021
★★★★★ 4.84 (128 Ratings) • 3,000+ Students Enrolled
I strongly believe that if you had the right teacher you could master computer vision and deep learning.
Do you think learning computer vision and deep learning has to be time-consuming, overwhelming, and complicated? Or has to involve complex mathematics and equations? Or requires a degree in computer science?
That’s not the case.
All you need to master computer vision and deep learning is for someone to explain things to you in simple, intuitive terms. And that’s exactly what I do. My mission is to change education and how complex Artificial Intelligence topics are taught.
If you're serious about learning computer vision, your next stop should be PyImageSearch University, the most comprehensive computer vision, deep learning, and OpenCV course online today. Here you’ll learn how to successfully and confidently apply computer vision to your work, research, and projects. Join me in computer vision mastery.
Inside PyImageSearch University you'll find:
- ✓ 30+ courses on essential computer vision, deep learning, and OpenCV topics
- ✓ 30+ Certificates of Completion
- ✓ 39h 44m on-demand video
- ✓ Brand new courses released every month, ensuring you can keep up with state-of-the-art techniques
- ✓ Pre-configured Jupyter Notebooks in Google Colab
- ✓ Run all code examples in your web browser — works on Windows, macOS, and Linux (no dev environment configuration required!)
- ✓ Access to centralized code repos for all 500+ tutorials on PyImageSearch
- ✓ Easy one-click downloads for code, datasets, pre-trained models, etc.
- ✓ Access on mobile, laptop, desktop, etc.
Summary
I cannot emphasize enough how important the reproduction of results is in today’s research world. Especially in machine learning, we’ve slowly reached a point where novel research ideas are getting more complex day by day. In a situation like that, researchers having a platform to easily make their research and results public takes a huge burden.
When you already have enough things to worry about as a researcher, having the tool to make your model and results public using a single script and a few lines of code is a great boon for us. Of course, as a project, Torch Hub will evolve more according to the user’s needs as days progress. Regardless of that, the ecosystem advocated by the creation of Torch Hub will help Machine Learning enthusiasts for generations to come.
Citation Information
Chakraborty, D. “Torch Hub Series #1: Introduction to Torch Hub,” PyImageSearch, 2021, https://hcl.pyimagesearch.com/2021/12/20/torch-hub-series-1-introduction-to-torch-hub/
@article{dev_2021_THS1,
author = {Devjyoti Chakraborty},
title = {{Torch Hub} Series \#1: Introduction to {Torch Hub}},
journal = {PyImageSearch},
year = {2021},
note = {https://hcl.pyimagesearch.com/2021/12/20/torch-hub-series-1-introduction-to-torch-hub/},
}
Want free GPU credits to train models?
- We used Jarvislabs.ai, a GPU cloud, for all the experiments.
- We are proud to offer PyImageSearch University students $20 worth of Jarvislabs.ai GPU cloud credits. Join PyImageSearch University and claim your $20 credit here.
In Deep Learning, we need to train Neural Networks. These Neural Networks can be trained on a CPU but take a lot of time. Moreover, sometimes these networks do not even fit (run) on a CPU.
To overcome this problem, we use GPUs. The problem is these GPUs are expensive and become outdated quickly.
GPUs are great because they take your Neural Network and train it quickly. The problem is that GPUs are expensive, so you don’t want to buy one and use it only occasionally. Cloud GPUs let you use a GPU and only pay for the time you are running the GPU. It’s a brilliant idea that saves you money.
JarvisLabs provides the best-in-class GPUs, and PyImageSearch University students get between 10 - 50 hours on a world-class GPU (time depends on the specific GPU you select).
This gives you a chance to test-drive a monstrously powerful GPU on any of our tutorials in a jiffy. So join PyImageSearch University today and try for yourself.
To download the source code to this post (and be notified when future tutorials are published here on PyImageSearch), simply enter your email address in the form below!

Download the Source Code and FREE 17-page Resource Guide
Enter your email address below to get a .zip of the code and a FREE 17-page Resource Guide on Computer Vision, OpenCV, and Deep Learning. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL!

Comment section
Hey, Adrian Rosebrock here, author and creator of PyImageSearch. While I love hearing from readers, a couple years ago I made the tough decision to no longer offer 1:1 help over blog post comments.
At the time I was receiving 200+ emails per day and another 100+ blog post comments. I simply did not have the time to moderate and respond to them all, and the sheer volume of requests was taking a toll on me.
Instead, my goal is to do the most good for the computer vision, deep learning, and OpenCV community at large by focusing my time on authoring high-quality blog posts, tutorials, and books/courses.
If you need help learning computer vision and deep learning, I suggest you refer to my full catalog of books and courses — they have helped tens of thousands of developers, students, and researchers just like yourself learn Computer Vision, Deep Learning, and OpenCV.
Click here to browse my full catalog.